{kind=link}
本日発表された Dell のキャンペーン価格での 3007 WFP-HC の価格が \138,000。3 週間前にポチった時の価格は \188,000。僅か 3 週間で 5 万円も値下がりしてくれるとは。
「追加で 5 万出したから 3 週間早く使えたんだよ」と自分を騙そうと努力してはいるのだが、ちと無理っぽい。あー高価な 3 週間だったな。
ネット証券各社のサイトリニューアル(デザイン変更)が痛い今日この頃。この辺り でデータ取得元として使ってた所で軒並み HTML に変更が加わって、データ取得ができなくなってたときはどーしようかと思いましたよ。
変更が行われたのは5月の最終週で、まあ、変更された翌日には対応が可能だったから大した手間ではないのだけど、今後も半年おきぐらいで少しずつサイト変更が行われて、その度にこーゆー作業が発生するだろうと容易に想像できてしまうのは……ちと滅入る。
今はまだデータ取得と表示だけだから問題は少ないけど、将来的に発注まで自動化しようと考えるなら、この手のサイト変更だけで動かなくなるのは問題だよなぁ。うーむ、どーしよ。
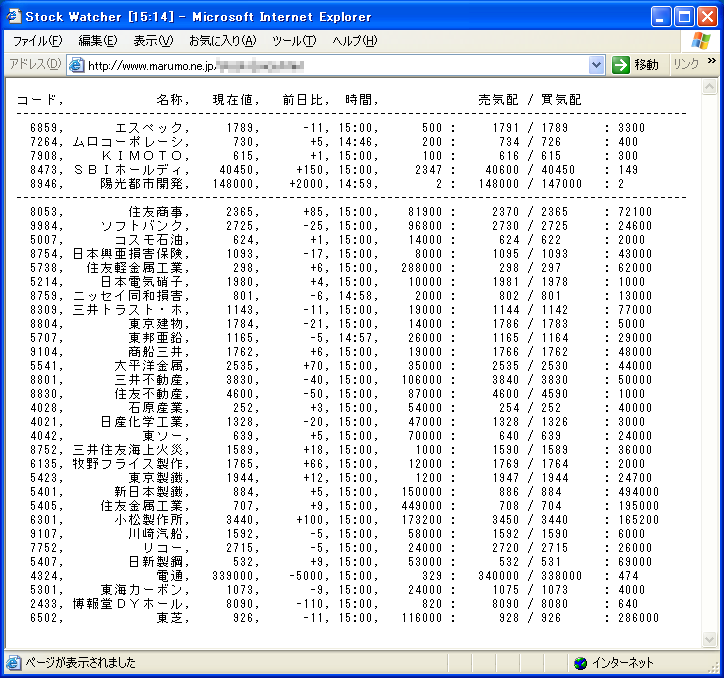
何が書いてあるのか判らない人向けの補足情報。ザラ場中に こんな形 で遅延が 1 分以内の株価と最良気配値を参照できるよーにしていた (昔 2ch 市況 1 板 SBI スレッドのテンプレートに載っていた「リアルタイム SBI アホルダー」をしょぼくしたよーなものを作ってた) のだけど、データ取得元に利用していた証券会社のサイトリニューアルのおかげで動かなくなっていたので、対応しなきゃいけなかったぜこんちきしょーという愚痴が今回の記述。
これは HTTPS のサポートと HTML パーサライブラリがあるスクリプト言語なら半日程度で作れるものなので、興味がある人は自力で何とかしてみることを推奨。ただ、データ取得元の HTML 形式がちょっぴり変更されただけであっさり動かなくなってしまうので……まーその場合も同じく半日程度で対応はできるんだけど……やっぱ無駄な労力だよなー。
ふと思い立って x264 (rev.658) の RD 曲線とか処理時間とかを調べてみた。使ったバイナリは seraphy さんの ICC ビルド。
|
|
|
|
|
|
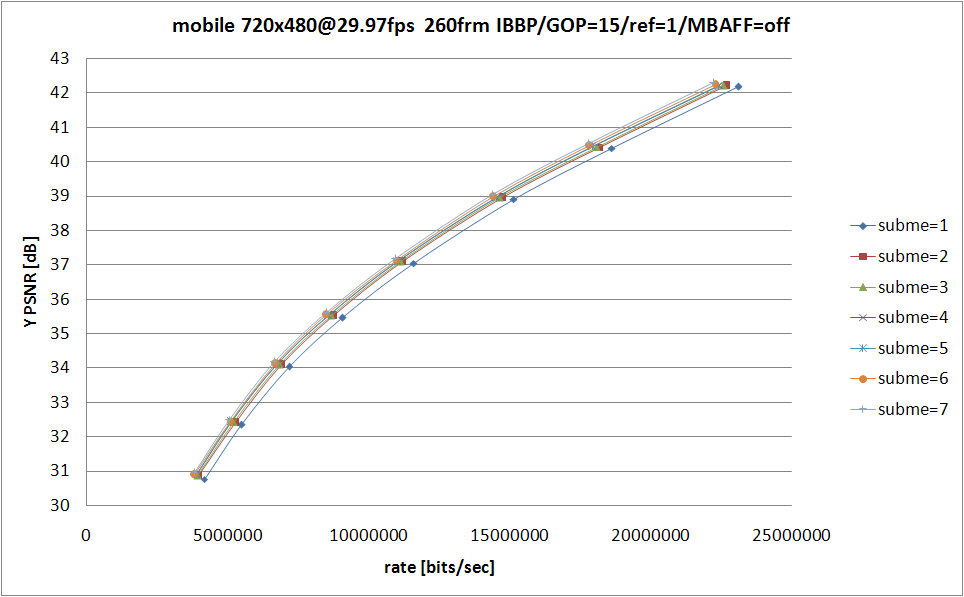
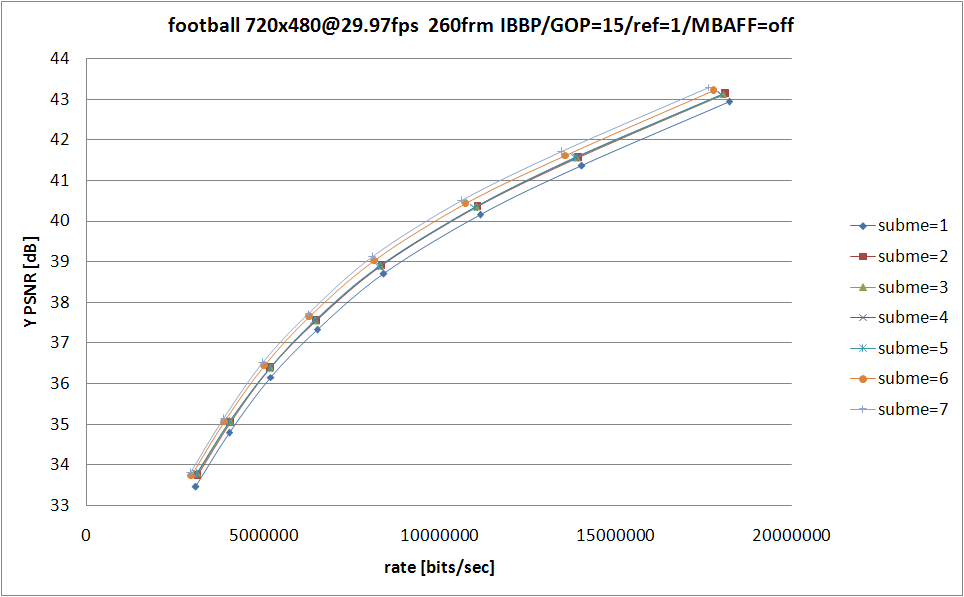
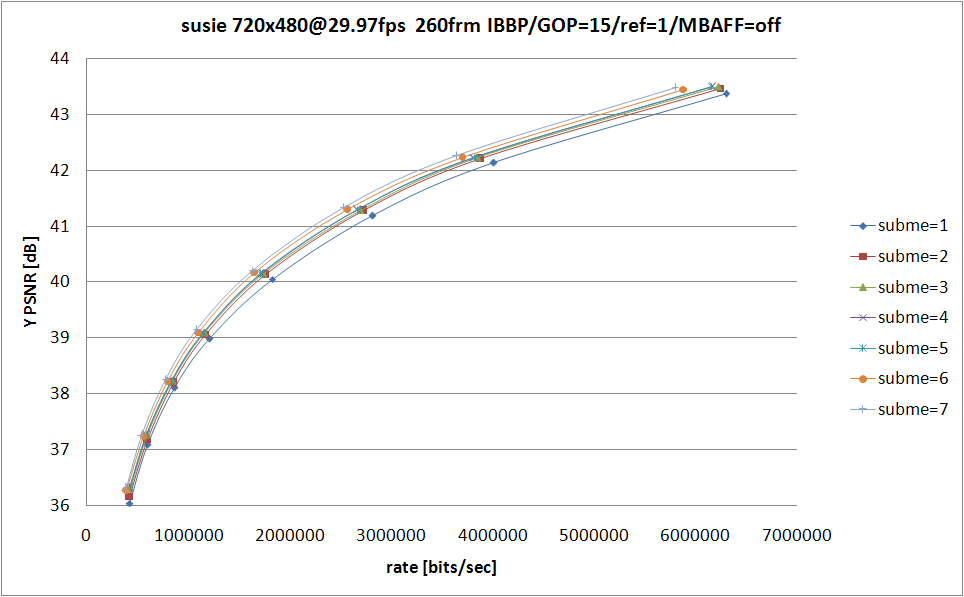
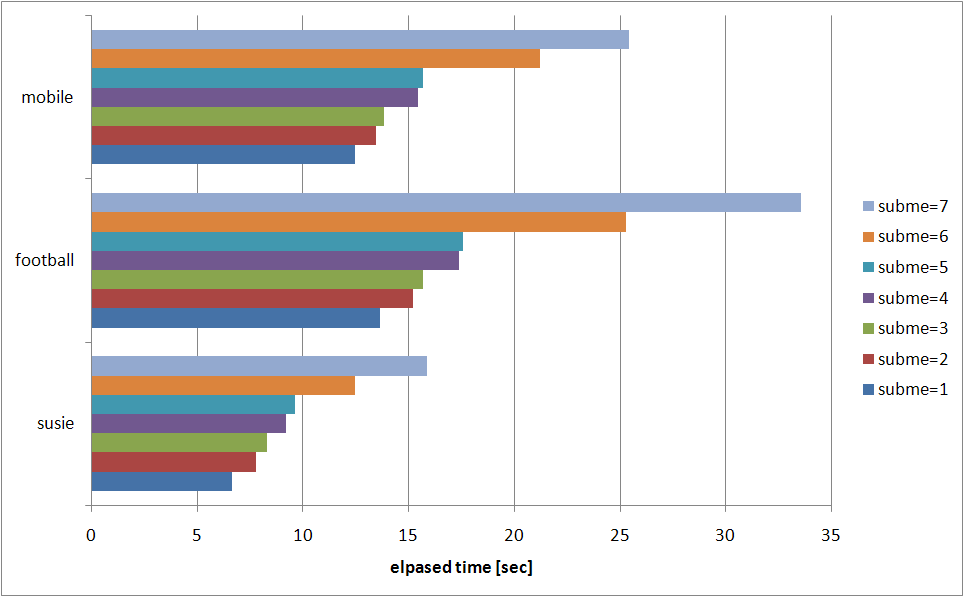
今回は --subme を 1〜7 まで振ってみた。QP の範囲は 18〜32。固定オプションに関しては以下を指定。
--keyint 15 --min-keyint 15 --bframes 2 --ref 1 --ipratio 1.0 --pbratio 1.0 --me umh --merange 32 --no-psnr --no-ssim --no-chroma-me --8x8dct --partitions "p8x8,b8x8,i8x8,i4x4" --cqm flat --threads 3
基本的に MPEG-2 等となるべく共通な設定 (--keyint 15 と --min-keyint 15 で GOP=15 に固定、--bframes 2 で IBBP を指定、--ref 1 で参照フレーム数を 1 に限定してマルチプルリファレンスを無効) にして、あとは速度そこそこ画質それなりを目指してパラメータを指定したつもり。測定環境は Core 2 Duo E6400 (2.13GHz, L2 2M)
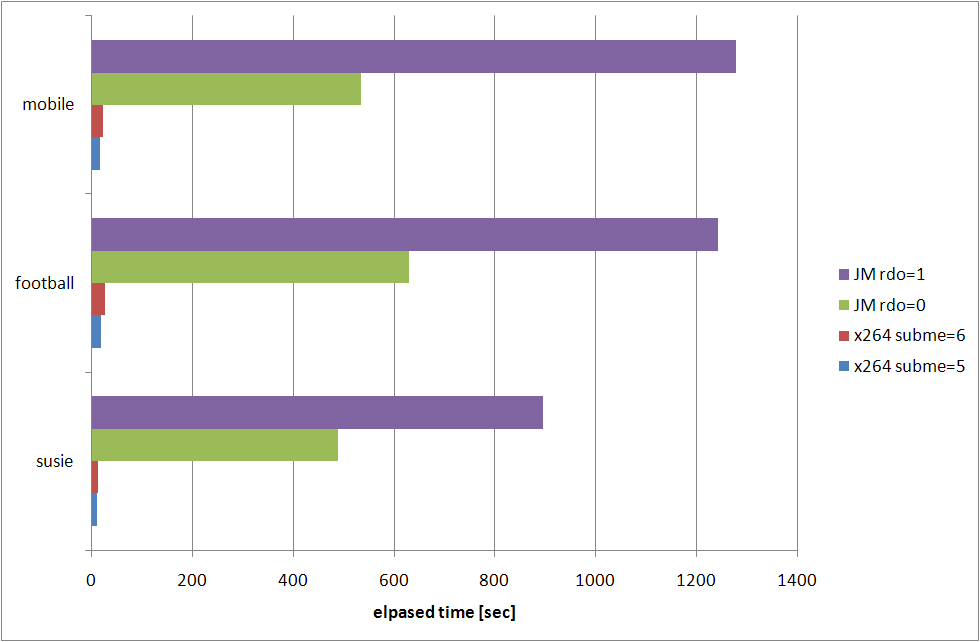
こーいったグラフから何が判るかというと、--subme オプションに関しては 1 は論外で、2〜5 は団子、6 および 7 では (より低い subme と比較して) 抜き出た RD 特性の改善が見られるてなことが言えたりする。実際のところ消費してる時間が増えるほど RD 特性は良くなっているというある意味当然の結果なんだけど。
グラフの簡単な解説。上に載せた 4 つのグラフのうち、右下の横棒グラフがエンコードの際に消費した時間を示したもので、それ以外の3つがいわゆる RD グラフと呼ばれるもの。RD グラフの縦軸は輝度 (Y) の平均 PSNR で、これは大きければ大きいほどエンコード結果と原画の間に誤差が少ない (つまり画質がいい) ということを示している。RD グラフの横軸はビットレートで、[bits/sec] でどれだけのデータを消費しているかということを示している。つまり RD グラフで左上に来るエンコーダほど、より少ないデータ量でよりよい画質を実現している、優れたエンコーダだという評価ができるわけだ。
で、横棒グラフは単純にエンコードの消費時間を視覚的に比較するためだけのグラフで、短ければ短いほど、短時間で処理が完了している優れたエンコーダだという評価になる。今回使ったソースは全て 260 フレームのものなので、8.67 (= 260/29.97) 秒以内に処理が完了している (susie の subme=1〜3) ものは、リアルタイム以上のスピードでエンコードできていることになる。
昨日の記述の中でエンコードソースとして使った mobile, football, susie は標準画像と呼ばれるもので、エンコーダの画質評価などで定番的に使われる素材だったりする。サンプル画像を以下に載せておく。

|

|

|
| mobile | football | susie |
それぞれ有名な画像なので、見たことのある人もいるかもしれない。ファイルサイズが 100M を超えるので動画全体のオリジナルファイルはこのサイトには置かないけど、VQEG の FTP サイト [CRC|ITS] や xiph.org のミラー [URI] から入手が可能。
mobile は src15_ref__525.yuv、football は src19_ref__525.yuv、susie は src21_ref__525.yuv がオリジナルファイルになる。オリジナルファイルは 720x486 の UYVY 形式なので、x264 に入力するためには下 6 ラインのクリップと UYVY から RAW 420 への変換が必要。
本当の標準画像は 898 フレーム (30 秒) 分あるのだけどネット上で誰もが入手できる形になってるのは VQEG の 260 フレームのものだけのようなので、今回はこちらを使用した。いちおー NDA とか気にしないといけない窮屈な身分なので。
720x480 解像度の動画なので、どれも 60i のインタレース映像になっている。当然インタレースを考慮したエンコード (--interlaced オプションを指定) をした方が原理的には良いはずなのだけど、その辺りは後々の更新のネタにとっておこうと昨日の段階では後回しにすることにした。
x264 だけで RD を眺めていてもあまり楽しくないので、JM との比較をしてみる。
|
|
|
|
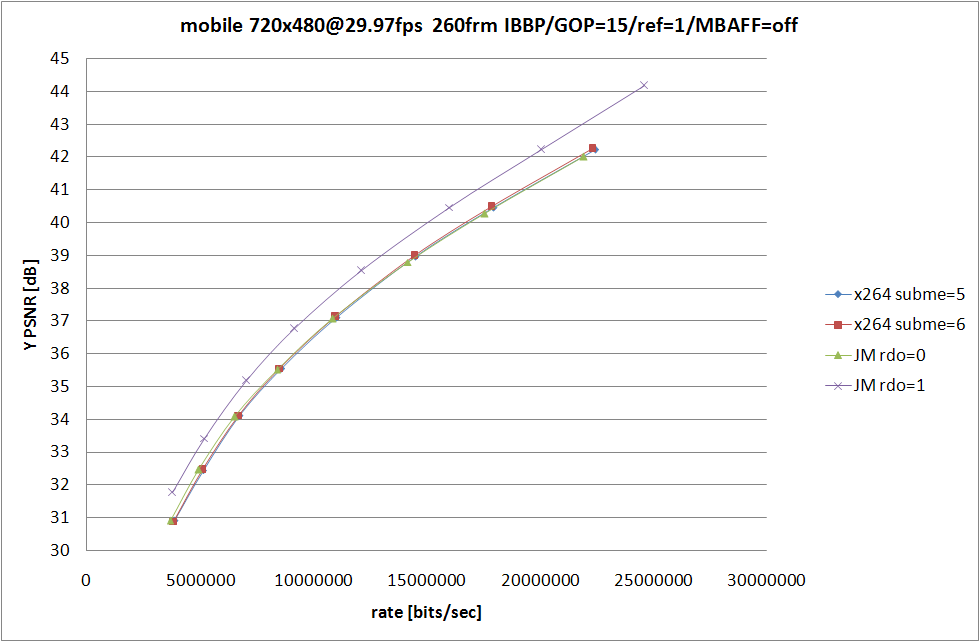
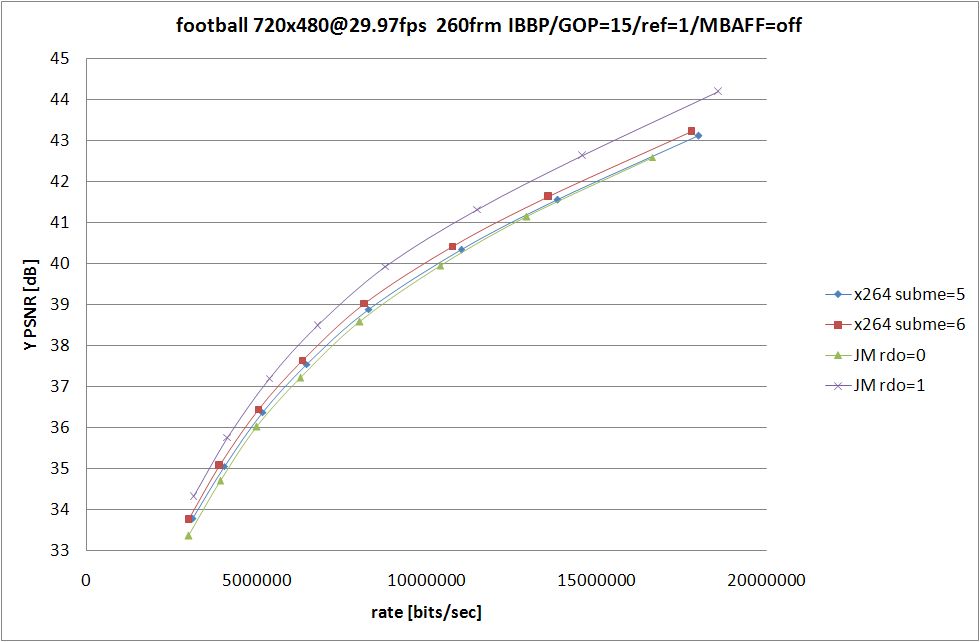
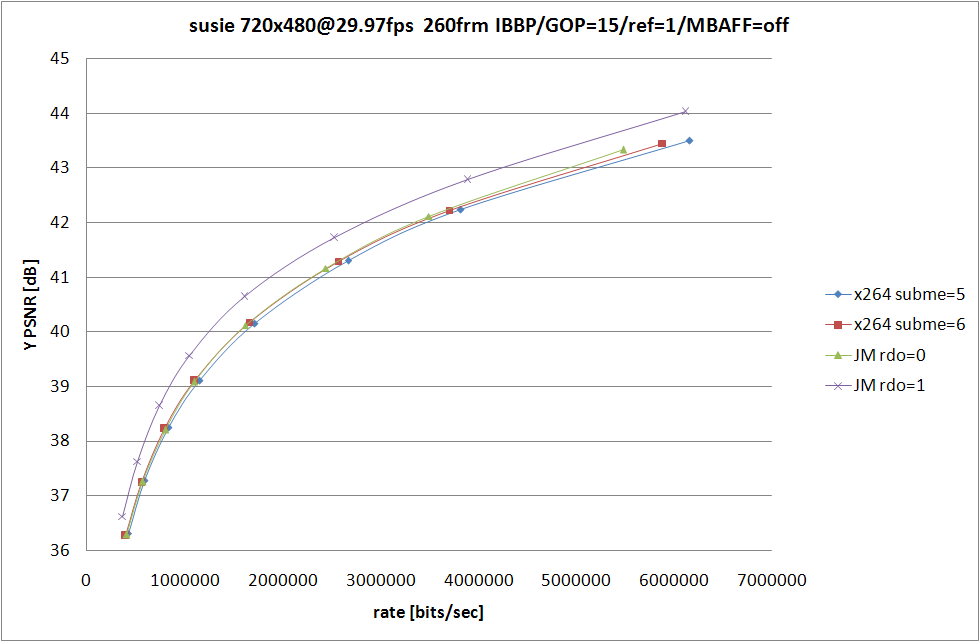
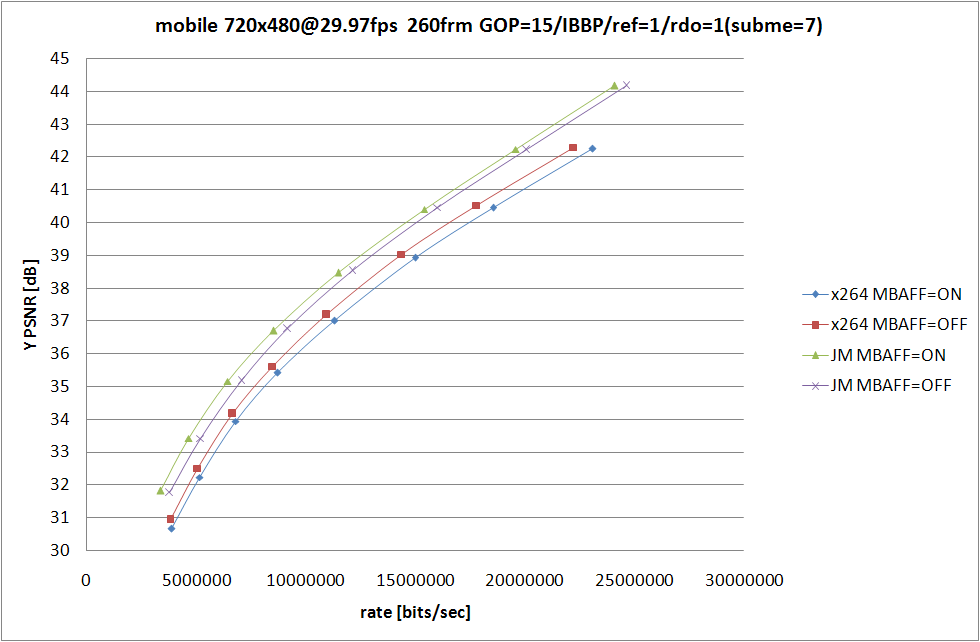
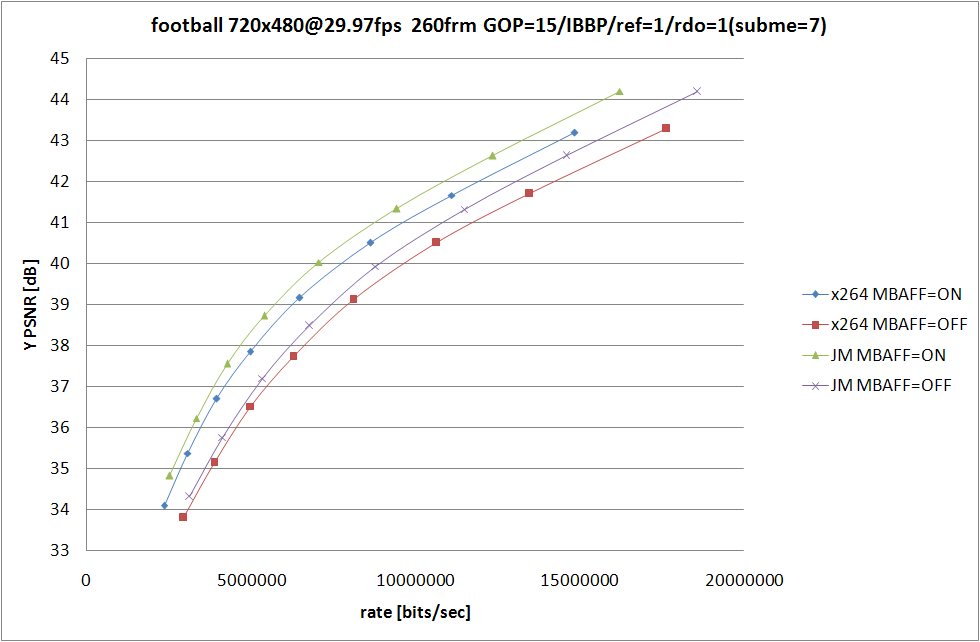
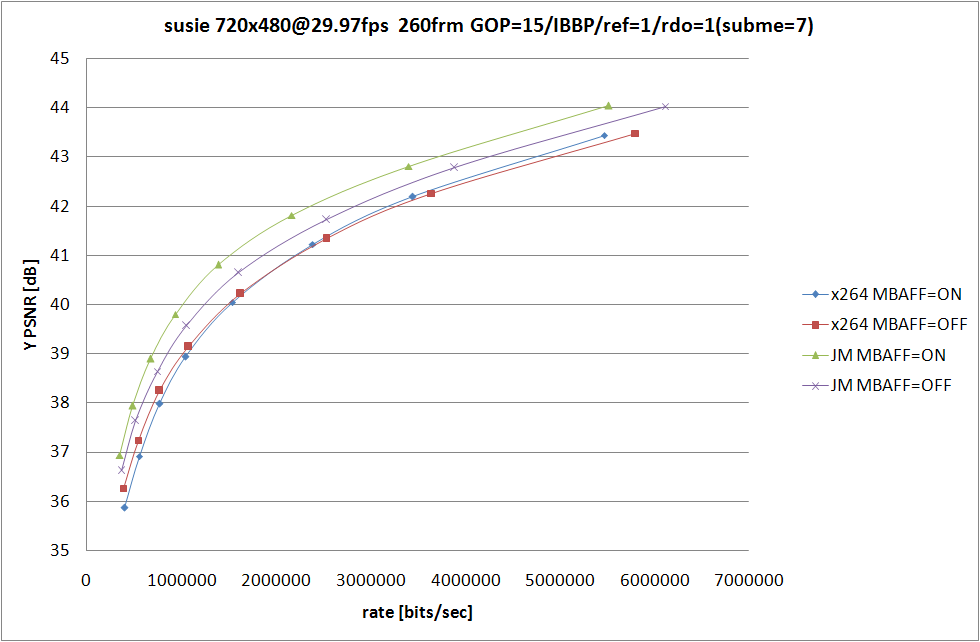
x264 側の条件は 前回 と同じで、なるべく条件が等しくなるように、RDO (Rate Distortion Optimization) が使われてない中で最も性能が良い --subme=5 と、RDO をモード選択にしか使っていない --subme=6 を残してみた。
JM の側は RDOptimization を 0 と 1 で切り替えて、ほかの設定に関してはなるべく x264 側と揃えたつもり。詳細なオプションは後で書くので、結果の考察を。
といっても見たまんまなのだが、JM での RDO の On/Off での RD の変化と比較して、x264 での RDO の On/Off での変化の小ささが目立つ訳で、あーやっぱ高速なだけあってそれなりに手抜きをしてるんだなぁと納得してしまうわけなのだ。エンコードスピードに関しては比較するのも馬鹿らしいほど差が付いてるので特に考察はしない。JM 側は SIMD も使ってないしマルチスレッド化もされてないから遅いのは仕方がないことのだけど、遅い原因はそれだけじゃなくてコードが腐ってる (データの持ち方が馬鹿な) あたりも大きな要素を占めてるのであまり弁護する気にならない。
んで、JM の詳細オプション。
InputFile = mobile.420 / football.420 / susie.420 InputHeaderLenght = 0 StartFrame = 0 FrameToBeEncoded = 86 # 260/(2+1) を設定 FrameRate = 29.97 SourceWidth = 720 SourceHeight = 480 IntraPeriod = 5 # 15/(2+1) を設定 EnableOpenGop = 0 # Closed GOP を使う IDRIntraEnable = 1 # I スライスは全て IDR 扱い QPISlice = 18〜32 QPPSlice = 18〜32 FrameSkip = 2 # 挿入予定の B ピクチャの数を設定 ChromaQPOffset = 0 DisableSubpelME = 0 # 1/2, 1/4 画素単位の動き検索を行う SearchRange = 32 # 動き検索範囲は ±32 画素 MEDistortionFPel = 0 # 画素単位の動き検索では SAD を使い MEDistortionHPel = 2 # 1/2 画素単位の動き検索では SATD を使う MEDistortionQPel = 2 # 1/4 画素単位の動き検索でも SATD を使う MDDistortion = 2 # モード選択時も SATD を使う ChromaMCBuffer = 1 ChromaMEEnable = 0 NumberReferenceFrames = 2 # B では前後 2 枚の参照フレームが必要なので PList0References = 0 Log2MaxFNumMinus4 = 0 Log2MaxPOCLsbMinus4 = -1 GenerateMultiplePPS = 0 ResendPPS = 0 MbLineIntraUpdate = 0 RandomIntraMBRefresho = 0 InterSearch16x16 = 1 # インター 16x16 予測有効 InterSearch16x8 = 1 # インター 16x8 予測有効 InterSearch8x16 = 1 # インター 8x16 予測有効 InterSearch8x8 = 1 # インター 8x8 予測有効 InterSearch8x4 = 0 # インター 8x4 予測無効 InterSearch4x8 = 0 # インター 4x8 予測無効 InterSearch4x4 = 0 # インター 4x4 予測無効 IntraDisableInterOnly = 0 # P/B スライスでもイントラ MB を使う Intra4x4ParDisable = 0 # イントラ予測は全モード有効 Intra4x4DiagDisable = 0 Intra4x4DirDisable = 0 Intra16x16ParDisable = 0 Intra16x16PlaneDisable = 0 ChromaIntraDisable = 0 EnableIPCM = 0 # イントラ PCM モード無効 DisposableP = 0 DispPQPOffset = 0 NumberBFrames = 2 # IBBP 形式で B を 2 枚挿入 QPBSlice = 18〜32 DirectModeType = 0 # B スライスのダイレクトモードは temporal を指定 DirectInferenceFlag = 1 # direct_8x8_infernece=1 で運用 BList0References = 0 BList1References = 1 # 後方参照は 1 枚しか参照フレームに使わない BReferencePicture = 0 # 全ての B を非参照フレームに BiPredMotionEstimation = 1 BiPredMERefinements = 3 BiPredMESearchRange = 16 BiPredMESubPel = 2 SPPicturePeriodicity = 0 # SP スライス無効 SymbolMode = 1 # CABAC 使用 OutFileMode = 0 # 264 ES 形式で出力 PartitionMode = 0 ContextInitMethod = 0 # cabac_init_idc は FixedModelNumber = 0 # 0 に固定 PicInterlace = 0 # 全てフレームピクチャ MbInterlace = 0 # MBAFF 無効 (有効にする為には RDO=1 が必要) WeightedPrediction = 0 # 重み付き予測無効 RDPictureDecision = 0 RDPictureIntra = 0 LoopFilterParametersFlag = 0 # デフォルトのデブロックフィルタを利用 SliceMode = 0 # ASO 無効 UseRedundantPicture = 0 # 冗長ピクチャ無効 RestrictSearchRange = 2 # 検索範囲制限無し RDOptimization = 0/1 # RDO 無効と有効でエンコード CtxAdptLagrangeMult = 0 # 固定の lambda (bit_to_cost 係数) を使う FastCrIntraDecision = 1 # イントラ MB の色差予測を高速に DisableThresholding = 0 # DCT 係数の切り捨てを行う DisableBSkipRDO = 0 SkipIntraInInterSlices = 0 # P/B スライスでもイントラ MB を使う UseExplicitLambdaParams = 0 # 初期値の lambad を使う UseConstrainedIntraPred = 0 # インター MB からのイントラ予測を可能にする LastFrameNumber = 259 # 最終フレームは 260-1 の 259 ChangeQPStart = 0 # QP は変更せず最後まで同じものを使う PicOrderCntType = 0 # POC type は 0 (B を使う場合は 0 にする必要がある) RateControlEnable = 0 # レートコントロール無効 (固定 QP でエンコードするため) EarlySkipEnable = 0 # スキップモードを調べただけで処理を打ち切らない SelectiveIntraEnable = 0 YUVFormat = 1 # YUV 420 形式 RGBInput = 0 # 1=RGB input, 0=GBR or YUV input BitDepthLuma = 8 # 8 bit 入力 BitDepthChroma = 8 CbQPOffset = 0 # 色差も輝度と同 QP でエンコード CrQPOffset = 0 Transform8x8Mode = 1 # 8x8 DCT 有効 ReportFrameStats = 0 # フレームログを出力しない DisplayEncParams = 0 # エンコードパラメータを出力しない Verbose = 0 # ログは簡潔に ScalingMatrixPresentFlag = 0 # 重み付き量子化は使わない (flat 16 を使う) OffsetMatrixPresentFlag = 0 # 量子化時の丸め行列は初期値を使う AdaptiveRounding = 1 # 量子化時の丸め行列を適応的に変更する (アルゴリズムの詳細は JVT-N011 を参照) AdaptRndPeriod = 1 AdaptRndChroma = 1 AdaptRndWFactorIRef = 4 AdaptRndWFactorPRef = 4 AdaptRndWFactorBRef = 4 AdaptRndWFactorINRef = 4 AdaptRndWFactorPNRef = 4 AdaptRndWFactorBNRef = 4 AdaptRndCrWFactorIRef = 4 AdaptRndCrWFactorPRef = 4 AdaptRndCrWFactorBRef = 4 AdaptRndCrWFactorINRef = 4 AdaptRndCrWFactorPNRef = 4 AdaptRndCrWFactorBNRef = 4 QPPrimeYZeroTransformBypassFlag = 0 # QP=0 時でもロスレスモードを使わない SearchMode = 1 # 画素レベル検索に UMHexagon を使用 UMHexDSR = 1 UMHexScale = 3 ToneMappingSEIPresentFlag = 0 Generate_SEIVUI = 0 # VUI を出力しない
どーでもいい部分に関してはかなり省略しているのだけど、それでも長大になってしまう。x264 では --trellis を指定していないのに AdaptiveRounding を 1 にしてしまっているとか、--bime を指定していないのに BiPredMotionEstimation を 1 にしてしまっているとか、--no-fast-pskip を指定していないのに EarlySkipEnable を 0 にしてしまっているとか、いくつか設定ミスもあるのだけど、再測定は時間がかかりすぎるので行わない方向で。エンコードにかかる時間が多少短くなるぐらいでさほど結果に違いはないはずだから。
JM が遅すぎて今回の更新にバッチ処理が間に合わなかったので、穴埋め企画。RD グラフの描き方。
といっても、固定 QP で複数回 (QPを変化させて) エンコードを行い、x 軸にビットレート (あるいはファイルサイズ)、y 軸に輝度の PSNR を取って、エクセル (あるいは他のグラフソフト) で平滑線つき散布図グラフを描きましょうで終わってしまうのは短すぎるので、もすこし膨らましておく。
x264 も JM も、エンコード時点で PSNR を計算してログ出力する機能をもっているので、手間さえ惜しまなければ特別な道具を使わなくても RD グラフを描くことはできる。だけど、普通の人は多分 2 セット目のデータ録りを始めたあたりで、出力ファイルサイズを記録して、ログファイルから SNR 値を拾ってという作業の不毛さに嫌気がさしてくるのではないかと思う。
私も最初のうちは地道に手作業でデータ録りをしていたのだけど、途中からバッチ用のスクリプトを書いて、そちらにある程度データの整理まで済ませたタブ区切りテキストを出力させる形に逃げてしまった。スクリプトはだいたい次のような手順になる。
実際のスクリプトは jm.rb とかを使っている。このスクリプトは以下のフォルダ構成で動作させることを前提にしている。
+ 作業用トップフォルダ
+ bin (実行ファイル格納用フォルダ)
- lencod.exe (JM のエンコーダ実行ファイル)
- ldecod.exe (JM のデコーダ実行ファイル)
- yuvsnr.exe (RAW 420 ファイル同士の SNR 算出用実行ファイル)
+ yuv (オリジナル RAW 420 ファイル保存用フォルダ)
- mobile.420
- football.420
- susie.420
- encoder.cfg (JM のエンコーダ用設定ファイル)
- decoder.cfg (JM のデコーダ用設定ファイル)
- jm.rb (スクリプト本体)
実際に動かした場合の出力は次のような形になる。
tag=susie, gop15, bfrm=2, cabac=1, cost_function=1, pred=3, t8x8=1, matrix=0, mbaff=0, rdo=0 qp bps snr sec 18 5485726.320923 43.330000 497.594000 20 3494361.832615 42.110000 488.032000 22 2443088.927077 41.160000 484.937000 24 1620914.078769 40.120000 479.953000 26 1098332.260615 39.080000 478.156000 28 803840.585538 38.210000 474.547000 30 573611.967692 37.250000 472.797000 32 409331.182154 36.280000 470.094000 tag=susie, gop15, bfrm=2, cabac=1, cost_function=1, pred=3, t8x8=1, matrix=0, mbaff=0, rdo=1 qp bps snr sec 18 6118465.871077 44.030000 957.063000 20 3888108.614769 42.780000 896.312000 22 2534961.270462 41.720000 858.203000 24 1610717.823692 40.640000 824.187000 26 1054210.887692 39.570000 797.672000 28 743726.298462 38.640000 783.906000 30 518026.378154 37.630000 767.641000 32 364883.366769 36.620000 753.406000
スクリプトを動かすためには、以下のものが必要になる。
なるべく誰でも再現環境が構築できるように書くつもりだったのだけど…… JM がビルド済みバイナリを配布していないおかげで敷居が高くなってしまった。JM には VC++ 2005 用のプロジェクトファイルが用意されているので VC++ 2005 Express をインストールして vc8.sln を開き、lencod と ldecod をビルドするだけなんだけど、それだけが難しい人もいるんだよなぁ。
さて、以上が私の場合の RD グラフの描き方になる。上でサンプルとして載せたログが手に入ったら、後は表計算ソフトにコピーして、適当にデータを選択してグラフを描かせるというという手順で RD グラフを描いている。さらに自動化を進めてグラフ画像自体をスクリプトから出力とかも不可能ではないのだけど、そこまでやるほどの価値はないかと考えてこの手法に落ち着いている。
JM ではなく x264 を使う場合でも lencod が x264 に変わって、エンコーダオプションも変化する程度で他の仕組みはほとんど変化しない。
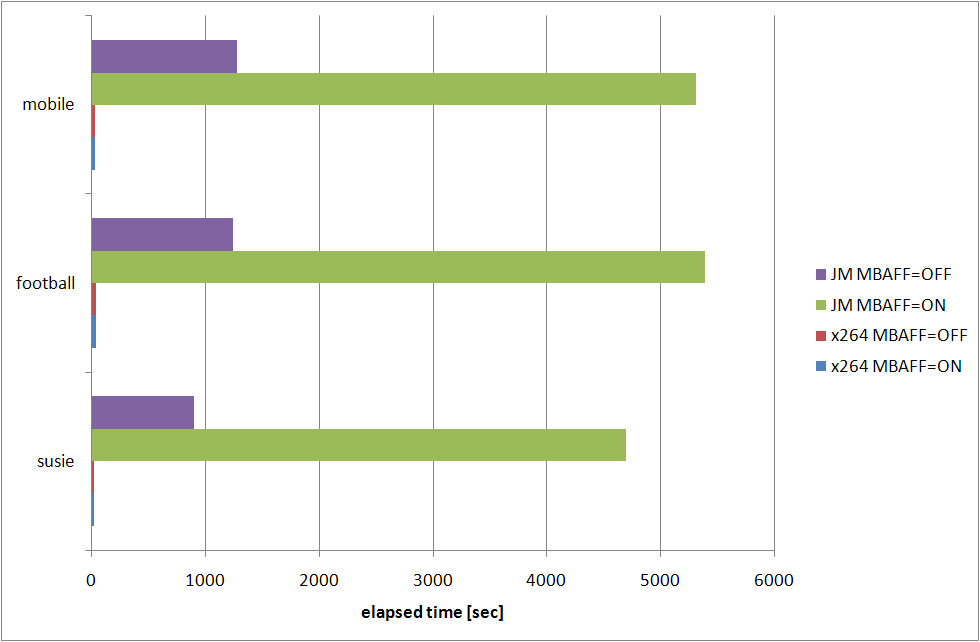
インタレースコンテンツに対して、x264 の --interlaced オプション (MBAFF 機能) を使うとどうなるか。とりあえず恒例の RD グラフから。
|
|
|
|
x264 で --subme 7 状態で --interlaced を指定したもの (MBAFF=ON) と指定しなかったもの (MBAFF=OFF) と JM で RDOptimization=1 状態で MbInterlace を 0 (MBAFF=ON) と 2 (MBAFF=ON) で切り替えたものを比較してみた。
結果、football だけは x264 でも MBAFF を使ったものの方が良い結果となっているものの、susie の低レート (qp>24) と mobile の全てで MBAFF を使わない側の RD 曲線が上にきている。しかし、JM ではそのようなことはなく 3 コンテンツ全てで MBAFF を有効にしたものが良い結果となっている。
何故こんなことが発生するのか。それを説明する前に、コーデックとしてのインタレース対応とは何かということを説明しておく。
まず、インタレースコンテンツには縞がある。トップフィールドの存在する (撮影された) 時間とボトムフィールドの存在する (撮影された) 時間が異なるため、フィールド毎に違う絵が存在することとなり、組み合わせて見れば縞が見えてしまう。
次に、違う絵が組み合わさって縞ができた絵を何も考えずに MC+DCT で圧縮しようとすると、圧縮効率が非常に悪くなってしまう。そこで、縞があることを前提に、特別な処理を加えることで縞があっても圧縮効率が落ちないようにしようというのがコーデックでのインタレース対応だ。
DirectShow のレンダラーにインタレースフラグが通知されて、レンダラーレベルのインタレース解除が行われて縞が出なくなるというのはあくまでもオマケ的な効果で、本来のコーデックのインタレース対応の目的じゃない。コーデックでのインタレース対応の目的はむしろ、縞を縞のまま奇麗に残す (ただし、余計なデータは増やすことなく) ところにある。
そんじゃ MBAFF では縞を奇麗に残すためにどーしてるのか。MBAFF を使わない場合、H.264/AVC では一つの映像フレームを 16x16 の小さな単位 (これをマクロブロックと呼ぶ) に分けて、一つずつ圧縮していく。MBAFF を使う場合は分割単位が 16x16 から 16x32 に変化する。そして、16x32 の中に縞があればトップとボトムの 16x16 二つに分けて圧縮する。縞がなければ上下の 16x16 二つに分けて圧縮する。縞があるときとない時でマクロブロック (MB) を適応的 (Adaptive) に、Field と Frame を切り替えて圧縮するのが MBAFF だ。


上に載せた絵の、左側は football の一部を拡大したもので、右側は mobile の一部を拡大したものだ。左側はトップ/ボトムで分けるフィールドモードが適切で、右側は上/下で分けるフレームモードが適切な例になる。しかし x264 (rev.658) の --interlaced オプションは全ての MB ペアをフィールドモード固定で処理するという割り切った仕様になっているため、冒頭に載せた RD グラフのように JM では MBAFF を使った方が RD 性能が良くなるものでも、x264 では MBAFF を使わない方が RD 性能が良いとかいう結果になってしまうわけなのだ。
ただ、個人的には x264 の仕様を非難する気にはなれない。MBAFF を有効にした場合の JM の処理時間 (実に無効時の 4 倍に増加) を見て、それでも MBAFF を適応的にしてくれと言う人は少ないのじゃないかなーと思う。実際私も過去に「インタレースなんてこの世から消えてなくなってしまえ」と呪詛を放った記憶があるし。
今回は --no-fast-pskip の効果について。これは低レート (高 QP) で平坦な場所にノイズが乗ることがあるのを防ぐために追加されたオプションということになっている。ただ、実際にはどんなノイズが出るのか知らない人も多いと思うので実例を。
上の動画 (再生には Flash Plug-In が必要) は左側が --no-fast-pskip を「指定しない」でエンコードしたもので、右側が --no-fast-pskip を「指定して」エンコードしたものになっている。この動画を再生すると、左側でのみ、枝の一部が背景の空に残ってしまっているのが確認できると思う。(注 : 判りやすくする為に、動画内では問題部分を拡大表示している)
エンコードソースは media.xiph.org からダウンロードした flower [sif 150frm] を使い、--no-fast-pskip 以外のオプションについては以下を指定している。
--keyint 15 --min-keyint 15 --bframes 0 --ref 1 --ipratio 1.0 --pbratio 1.0 --me umh --merange 32 --no-psnr --no-ssim --no-chroma-me --8x8dct --partitions "p8x8,b8x8,i8x8,i4x4" --cqm flat --qp 32 --subme 5
エンコーダの最適化で定番的に使われる手法として、「スキップ MB と判定できる場合は他のモードを調べずに処理を省く」というものがある。ただ、この flower garden のように、背景 (この場合は空) の上で微妙な物体 (この場合は細い枝) が動いているシーンでは、MB の極一部にだけ微妙な物体が掛っている場合に (本来なら設定すべきではない) スキップ MB として MB モードを決定してしまい、正しい MV を持っていれば残らなかったはずの一部だけ差し掛かっている物体が延々引きずるように動画内に残ってしまうことがある。
--no-fast-pskip というのはこれを避けるために用意されたもので、「P ピクチャではスキップ MB と判定できても、一応動き検索を行う」という処理にエンコーダの挙動を変更させるためのオプションだ。速度はそれほど遅くならないので、常に指定した方が良いと思う。
H.264 では極端に小さな数字を設定した量子化行列には意味がない。ばかりか、むしろ弊害が多い。たとえば次の二つの設定は、量子化処理だけを見れば同じ結果をもたらす。
qp: 26, matrix: 2, 4, 6, 8, 4, 4, 8, 12, 6, 8, 12, 14, 8, 12, 14, 16, qp: 20, matrix: 4, 8, 12, 16, 8, 8, 16, 24, 12, 16, 24, 28, 16, 24, 28, 32,
この設定は qp を 6 減らして、matrix の数値を倍に増やしたものだ。この設定が同じ量子化結果をもたらすことを順を追って説明していく。
イントラ 4x4 DCT 係数の量子化処理を (JM の処理を踏襲して) 簡略化したコードサンプルで示すと次の形になる。
int16_t post_scale[6][16] = {
{
13107, 8066, 13107, 8066,
8066, 5243, 8066, 5243,
13107, 8066, 13107, 8066,
8066, 5243, 8066, 5243,
},{
11916, 7490, 11916, 7490,
7490, 4660, 7490, 4660,
11916, 7490, 11916, 7490,
7490, 4660, 4660, 4660,
},{
10082, 6554, 10082, 6554,
6554, 4194, 6554, 4194,
10082, 6554, 10082, 6554,
6554, 4194, 4194, 4194,
},{
9362, 5825, 9362, 5825,
5825, 3647, 5825, 3647,
9362, 5825, 9362, 5825,
5825, 3647, 5825, 3647,
},{
8192, 5243, 8192, 5243,
5243, 3355, 5243, 3355,
8192, 5243, 8192, 5243,
5243, 3355, 5243, 3355,
},{
7282, 4559, 7282, 4559,
4559, 2893, 4559, 2893,
7282, 4559, 7282, 4559,
4559, 2893, 4559, 2893,
},
};
void quant_intra_4x4(int16_t *coeff, int16_t *matrix, int qp)
{
int i;
int w,m;
int round;
int qp_per;
int qp_rem;
qp_per = qp / 6;
qp_rem = qp % 6;
round = (1<<(15+qp_per)) / 3;
for(i=0;i<16;i++){
// 本当は coeff[i] < 0 の時は別の処理にしなければ
// いけないのだけど、判りやすさを優先して省略
m = post_scale[qp_rem][i] * 16 / matrix[i];
w = coeff[i] * m;
coeff[i] = (w + round) >> (15+qp_per);
}
}
quant_intra_4x4() の入出力について説明しておく。coeff は関数呼び出し前は DCT 後の係数値で、呼出し後は、量子化後の (CAVLC/CABAC で圧縮される) 係数値。matrix は x264 の --cqmfile オプション等で指定できる量子化行列。qp は --qp パラメータでおなじみの品質値。
post_scale という一見意味不明のテーブルがあるけれども、それ以外はシンプルでそんなに難しくない処理のはず。とりあえず具体的な数字で見た方が判りやすいと思うので、coeff[0] が 64 で、matrix[0] が JVT デフォルト行列の 6、qp が 20 の場合に、出力 coeff[0] はどうなるか計算してみる。
qp_per : 20 / 6 = 3 qp_rem : 20 % 6 = 2 round : (1<<(15+3)) / 3 = 87381 m : 10082 * 16 / 6 = 26885 w : 64 * 26885 = 1720640 coeff[0] : (1720640 + 87381) >> (15+3) = 6
というわけで、coeff[0]=64 は JVT のデフォルト量子化行列で qp=20 の場合には 6 へ量子化される。
同様に coeff[0]=64, matrix[0]=6 で qp=26 の場合を見てみる。
qp_per : 26 / 6 = 4 qp_rem : 26 % 6 = 2 round : (1<<(15+4)) / 3 = 174762 m : 10082 * 16 / 6 = 26885 w : 64 * 26885 = 1720640 coeff[0] : (1720640 + 174762) >> (15+4) = 3
qp が 6 増えると、量子化後の値は 6 -> 3 と半分になることが確認できる。処理的には右シフトビット数が 1 増えるだけで他は変わらないから当然といえば当然なのだけど。同様に qp を 6 減らせば量子化後の値は倍になるし、qp はそのままで matrix の値を半分にすれば (m が倍になるので) 量子化後の値は倍になる。最初に出した設定例のように qp を 6 減らして matrix の値を倍にすれば量子化後の値は変化しない。
極端に小さな matrix を使うことは、qp を下げるのと同じ量子化効果を持つので、圧縮に伴う画質劣化は減少する。しかし、デブロックフィルタはオリジナル qp と同じ画質劣化があることを前提にした強いフィルタをかけるので、デブロックフィルタでの画質劣化が上昇する。また、オリジナル qp と同等の画質劣化が発生することを前提にモード選択がおこなれてしまい、適切な RD 最適化が行われなくなる。さらに、エンコーダの実装によっては m が 16 bit の表現可能範囲をオーバーフローして、正しい演算結果が得られなくなる可能性すらある。
以上 3 点が極端に値の小さな matrix を使うことの弊害だ。個人的にはそんなことをするぐらいなら素直に qp を下げた方が仕合せになれると考えている。
x264 での量子化処理は MMX/SSE を使って PMULHUW で高速に処理するために JM とは計算方法が変更されていて、次のようなコードになっている。
int16_t post_scale[6][16] = {
// JM と中身は同じなので省略
};
void quant_intra_4x4(int16_t *coeff, int16_t *matrix, int qp)
{
int i;
int w,m;
uint16_t mf; // mf は 16bit 精度 (PMULHUW を使うための制限)
int round;
int qp_per;
int qp_rem;
qp_per = qp / 6;
qp_rem = qp % 6;
for(i=0;i<16;i++){
m = post_scale[qp_rem][i] * 16 / matrix[i];
if(qp_per < 1){
// matrix に 1〜5 を指定してると、ここで mf が
// オーバーフローしてエンコード結果はブッこわれる
mf = m << 1;
}else if(qp_per == 1){
// matrix に 1〜2 を指定してると、ここでも mf が
// オーバーフロー
mf = m;
}else{
// このあたりしか使わないと決めてるなら matrix に
// 好きな値を指定可能
mf = m >> (qp_per-1);
}
round = ((32-deadzone_intra)<<10) / mf;
// 本当は coeff[i] < 0 の時は別の処理にしなければ
// いけないのだけど、判りやすさを優先して省略
w = coeff[i] + round;
coeff[i] = (w * mf) >> (16); // この処理が PMULHUW に相当
}
}
とりあえず、JM の場合と同様に、coeff[0]=64, matrix[0]=6, qp=20 が入力された場合の、出力 coeff[0] がどうなるか処理を追ってみる。(deadzone_intra はデフォルトの 11 が設定されているとして)
qp_per : 20 / 6 = 3 qp_rem : 20 % 6 = 2 m : 10082 * 16 / 6 = 26885 mf : 26885 >> (3-1) = 6721 round : ((32-11)<<10) / 6721 = 3 w : 64 + 3 = 67 coeff[0] : (67 * 6721) >> (16) = 6
多少処理が変わっていても、JM と同じ結果になることが確認できる。さて、round および deadzone_intra の意味を判りやすく示すために、coeff[0]=6, matrix[0]=6, qp=20 が入力された場合のことを考えてみる。
qp_per : 20 / 6 = 3 qp_rem : 20 % 6 = 2 m : 10082 * 16 / 6 = 26885 mf : 26885 >> (3-1) = 6721 round : ((32-11)<<10) / 6721 = 3 w : 6 + 3 = 9 coeff[0] : (9 * 6721) >> (16) = 0
この場合、入力段階では 6 と僅かながら存在した coeff[0] は量子化によって 0 へと切り詰められ、圧縮データ内から削除されてしまう。では coeff[0]=6, matrix[0]=6, qp=20 を変えずに、deadzone_intra を 0 に変更した場合はどうなるだろうか。
qp_per : 20 / 6 = 3 qp_rem : 20 % 6 = 2 m : 10082 * 16 / 6 = 26885 mf : 26885 >> (3-1) = 6721 round : ((32-0)<<10) / 6721 = 4 w : 6 + 4 = 10 coeff[0] : (10 * 6721) >> (16) = 1
deadzone_intra を 11 から 0 へと変更すると、出力 coeff[0] は 1 となり、圧縮データ内に出力されて残るようになる。(当然その分ビットを消費してしまうのだが)
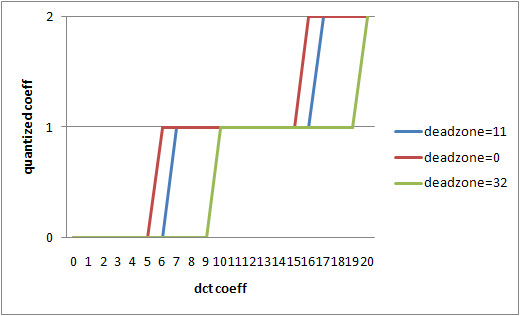
上のグラフは、deadzone を 11 (イントラでのデフォルト) と 0 (最小値) と 32 (最大値) で変化させた場合の量子化前後の入出力の対応を示したものになる。デッドゾーンが狭い (小さい) ほど、圧縮結果に残る DCT 係数値は多くなり、量子化誤差も (統計的には) 小さくなる。
x264 の --deadzone-intra / --deadzone-inter オプションは、量子化の際に 1 未満になる数字を、どうやって丸めるかという基準を設定するためのものだ。最小値の 0 を設定した場合は、量子化後のレベル基準で 0.5 以上を 1 へと切り上げ、0.5 未満を 0 へ切り下げる 4 捨 5 入の処理になり、最大値の 32 を設定した場合は 1 に満たないものはすべて 0 に切り捨てる処理になる。
量子化とデッドゾーン (丸めオフセット) の話をしたついでに、JVT 公式 FTP サイト [URI] から拾える興味深いドキュメントを紹介してみる。ファイル名は JVT-K026.zip で、2004_03_Munich ディレクトリの中にある。
この次期 (2003 年の暮れから 2004 年の半ばにかけて) は FRExt (現在の High/High422/High444 Profile) に向けて、どんな機能 (ツール) を追加すべきかということが話し合われていた。JVT-K026 は松下からの「量子化処理に際して (現在のような丸め方式ではなく) 明示的なデッドゾーンを導入しよう」という提案 (結局採用はされなかったはず) なのだけど、この中におもしろいことが書いてあるので、以下に引用してみる。
Note on a bug in the reference encoder:
For the results we presented, we removed a bug in the reference encoder. This bug leads to a non-optimal selection of the rounding control parameter f in P slices. As mentioned above, different f should be used in Intra or Inter mode. The current reference encoder selects this f on slice basis. This means that a different f are used depending on I or P slices. But if an intra macroblock is used in a P slice, the f from the P slice is assigned.
For all results, also for the current H.264/AVC results, this is corrected to a macroblock based selection. Without this correction, the results for current H.264/AVC are even worse.
適当に翻訳してみる。
リファレンスエンコーダ (訳注: JM のこと) のバグについて:
上の結果を示すために、私たちはリファレンスエンコーダからバグを取り除いた。バグによって P スライスでは不適切な丸め制御変数 f が選択されている。既に指摘したように、イントラ MB とインター MB では異なる f 値が選択されるべきである。現在のリファレンスエンコーダは f をスライス種別によって選択している。これは、異なる f が I スライスか P スライスかの違いに応じて選択されるということを意味している。つまり、P スライスでイントラ MB が使われた場合、P スライスに割り当てられた f 値が選択されてしまう。
上の結果すべては、現在の (訳注: Main Profile 当時の意味) H264/AVC の結果も含めて、このバグをマクロブロックタイプに応じて f を選択するように修正した後のものだ。修正前の状態であれば、現在の H264/AVC の結果は、もっと悪くなる。
えーと、上で使われている f 値というのは量子化の際の丸めオフセットのことで、x264 では昨日説明した --deadzone-inter / --deadzone-intra に相当するパラメータのこと。JM では I/IDR スライスならば 1/3 を使って、P/B スライスなら 1/6 を使っているのだけど、「そんなのはバグで、イントラ MB で 1/3 を、インター MB で 1/6 を丸めオフセットとして使うべきだ!!」というのが引用部分の主張している内容。
本田雅一のAV Trend - 最高品質を求めたBD版「パイレーツ」制作の裏側【後編】 で「さらに「詳細は秘密」とのことだが、エンコーダのソースコード自身にも手が入っている。ISOリファレンスのエンコーダに必要精度が出ていない部分を発見し、その部分の演算精度を向上させた」という記述を見たとき、最初に連想したのが、今回紹介した主張の件だったりする。ただ、パイレーツのエンコードの際に発見したなら時期が合わないし、すでに公知のものを「詳細は秘密」と言ったりはしないだろうということで何か他の問題を言ってるのだろうと考え直した。
このバグ (と PEL が主張しているもの) については、既に 3 年が経過した現在 (JM12.2) に至っても未だに放置 (オフセットマトリックスを明示的に指定すれば一応回避可能だけど、デフォルトパラメータでは放置) されている。なお、x264 ではスライスタイプに依らず、MB の イントラ / インターに応じて丸めオフセット (コード内では quant4_bias, quant8_bias という変数名になっている) を切り替える (PEL 側の主張に合う) 実装になっている。
今日は --no-dct-decimate について。こちらも --no-fast-pskip と同様に画質向上目的のオプションで、指定すると P フレームでの (量子化後の) DCT 係数の間引きを止めるようになる。とりあえずどんな効果があるかのサンプルを。
上の動画で左側は --no-dct-decimate を「指定しない」もので、右側は「指定した」もの。サンプル内でズームしてある場所を注意深く比較すると、右側には残っているのに左側ではなくなってるモノとか、左側にだけ奇妙なゴミが出てるのとかに気が付くと思う。
今回はエンコードソースは media.xiph.org からダウンロードしてきた tempete [CIF 260frm] を使って、--no-dct-decimate 以外のオプションについては以下を指定した。
--keyint 15 --min-keyint 15 --bframes 0 --ref 1 --ipratio 1.0 --pbratio 1.0 --me umh --merange 32 --no-psnr --no-ssim --no-chroma-me --8x8dct --partitions "p8x8,b8x8,i8x8,i4x4" --cqm flat --qp 32 --subme 5 --no-fast-pskip
--no-dct-decimate オプションで無効になる「DCT 係数の間引き処理」というのは JM 由来の処理 (規格で要求されている訳ではない) で、非常におーざっぱに説明すると、「量子化後の DCT 係数が小さくて少なければ、量子化で消えちゃったことにしちゃおーぜ」という内容のもの。
もう少し厳密な話をすると、8x8 ブロック内で、絶対値が 1 の係数が、2・3 個あるだけなら、そこの係数は全部 0 に間引きしてしまうという処理になっている。当然画質は悪くなるのだけど、その分ビットが節約できるからという理由で追加されている処理だ。
実際この処理を実行しないよりもした方がひじょーに、ひっじょーに僅かながら RD 性能の改善があるのだけど、個人的には flat16 matrix を使っている時以外は、常にこのオプションを有効にして、間引き処理を無効にしておいた方が良いと思う。次回、その辺りの詳細な理由を説明してみる。
予告どおり、JM/x264 共通で (標準では) 実行する DCT 係数の間引き処理について。とりあえず JM 12.2 の lencod/src/macroblock.c line 1272 から始まるコメントには次のように書かれている。
The purpose of the action below is to prevent that single or 'expensive' coefficients are coded. With 4x4 transform there is larger chance that a single coefficient in a 8x8 or 16x16 block may be nonzero. A single small (level=1) coefficient in a 8x8 block will cost: 3 or more bits for the coefficient, 4 bits for EOBs for the 4x4 blocks,possibly also more bits for CBP. Hence the total 'cost' of that single coefficient will typically be 10-12 bits which in a RD consideration is too much to justify the distortion improvement. The action below is to watch such 'single' coefficients and set the reconstructed block equal to the prediction according to a given criterium. The action is taken only for inter luma blocks.
必要ないよーな気もするけど、一応訳しておく。
以下の処理の目的は、単一の「高価」な係数が符号化されるのを防ぐことだ。 4x4 変換 (訳注 - DCT のこと) では単一の係数が非 0 となる機会が 8x8 や 16x16 変換よりも大きい。 単一の小さな (絶対値が 1 の) 係数が 8x8 ブロックの中にある場合、そのコストとして、係数自体の為に 3 ビットかそれ以上、 各 4x4 ブロックの EOB (訳注 - End Of Block - ブロック終端コード) の為に 4 ビット、そして CBP の為に更に数ビットが必要になる。 つまり、単一係数のトータル「コスト」は概ね 10〜12 ビットとなり、RD (訳注 Rate Distortion : 消費ビットと圧縮誤差) の観点からは、圧縮誤差の改善と比較して大きすぎる。 以下の処理でそれらの「単一の」係数を探し、与えられた基準に従って再構築ブロックを予測と同一 (訳注 - 予測誤差を DCT 係数として符号化しないという意味) にする。 この処理はインター輝度ブロックでのみ実行される。
まあ意図は理解できる。のだけど、とりあえず「単一の小さな係数」というのはデコード画像の画素値に変換するとどれぐらいの大きさになるのかを確認しておこうと思う。qp=26, matrix は flat と jvt の二種類で見てみる。
coeff jvt flat 1 0 0 0 1 1 1 1 3 3 3 3 0 0 0 0 1 1 1 1 3 3 3 3 0 0 0 0 1 1 1 1 3 3 3 3 0 0 0 0 1 1 1 1 3 3 3 3 coeff jvt flat 0 0 0 1 4 -7 7 -3 2 -4 4 -2 0 0 0 0 4 -7 7 -3 2 -4 4 -2 0 0 0 0 4 -7 7 -3 2 -4 4 -2 0 0 0 0 4 -7 7 -3 2 -4 4 -2 coeff jvt flat 0 0 0 0 3 -7 7 -3 1 -2 3 -1 0 0 0 0 -7 13 -13 7 -2 5 -5 3 0 0 0 0 7 -13 13 -7 3 -5 5 -2 0 0 0 1 -3 7 -7 3 -1 3 -2 1
上の例で coeff の欄に書いてある 4x4 の配列が入力値で jvt の欄に書かれているのが JVT のデフォルト行列を使っている場合に、入力値が、逆量子化および逆 DCT 処理後の差分値で実際に幾らになるかを示したもの。flat の欄は同様に flat 16 マトリックスを使った場合の復号差分値。(8x8 ブロックの中には他に 4x4 ブロックが 3 つあるけど、とりあえず残りは全部 0 だったと考えて省略する)
DCT 係数の間引き処理が行われなかった (x264 で --no-dct-decimate を指定していた) 場合は、参照フレームと動きベクトルで作成した予測ブロックに、上記の差分が追加されてデコード画像になる。DCT 係数の間引き処理を使った場合は、上記例は全て間引き対象ブロックとなり、係数値は全て 0 に、逆量子化および逆 DCT 後の復号差分値も 0 になり、参照フレームと動きベクトルから作成した予測ブロックがそのまま復号画像になる。
で、flat の場合と DC 係数しかない場合の jvt 例は差分値がなくなってもまあ気がつかないかなと思えるのだけど、残りの二つ、jvt マトリックスで高周波の AC 係数だけが存在する場合、本当に劣化に気がつかないだろうか。これぐらい大きな違いであれば、普通は気がついてしまうのじゃないかと思う。
実装にも奇妙なところがある。JM では (そのロジックをそのまま踏襲している x264 でも)、4x4 ブロックに複数の小さな係数があった場合でも、DCT 係数を間引けるように、DCT 係数の位置に応じたコストを足し合わせていって、それが閾値を超えなければ間引きを実行というロジックになっている。
で、その係数の位置によるコスト値というのが、周波数領域での絶対位置基準ではなく、スキャン順での run 値という相対位置で決定されるという仕組みになっている。以下に例を示すと
coeff 1 0 -1 0 0 0 0 0 0 0 0 0 0 0 0 0
上記ブロックはジグザグスキャン順に以下のように並び替えられる。
idx 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 level 1 0 0 0 0 -1 0 0 0 0 0 0 0 0 0 0 run 0 0 1 2 3 4 0 1 2 3 4 5 6 7 8 9
そして、次のテーブルから得たコスト値の和が 4x4 ブロックのコストになる。
cost_table[16] = {
3, 2, 2, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
}
具体的には、level が 0 ではない idx=0 と idx=5 の run 値を見て、以下のようにこの 4x4 ブロックのコストを 4 と算出する。
cost = cost_table[0] + cost_table[4] /* 3 + 1 = 4 */
DCT 係数の間引き処理を実行する閾値は 4 で、>= で比較しているので、このブロックは間引き対象となる。なお、量子化行列が flat の場合の復号後の差分値は以下になる。
0, 7, 7, 0, 0, 7, 7, 0, 0, 7, 7, 0, 0, 7, 7, 0,
で、これを行列転置しただけのものだと、スキャン順が近くなるので、コスト値が高くなり間引き対象外になる。以下に例を示す。
coeff 1 0 0 0 0 0 0 0 -1 0 0 0 0 0 0 0 idx 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 level 1 0 0 -1 0 0 0 0 0 0 0 0 0 0 0 0 run 0 0 1 2 0 1 2 3 4 5 6 7 8 9 10 11 cost = cost_table[0] + cost_table[2] /* 3 + 2 = 5 */
当然復号差分値も縦横ひっくり返るので、以下の形になるだけで、視覚特性的には変化しない。なのに、こちらは間引き対象外で、あちらは間引き対象。
0, 0, 0, 0, 7, 7, 7, 7, 7, 7, 7, 7, 0, 0, 0, 0,
奇妙でしょ? 周波数領域での絶対位置でコストを決めるなら、まだ flat16 しかなかった頃に、高周波領域を削除して量子化行列を使うのと同等の効果を狙って導入されたものかとも理解できなくはないのだけど、run 値での相対位置にしている理由はさっぱり推測不能。
以上が flat 16 以外の量子化行列を指定してる場合は DCT 係数の間引きは無効にした方がよいと考えている理由。正直 flat 16 と一緒に使ってる場合でも間引き判定のロジックは別の処理にした方が良いと思ってる。
Elecard の製品に StreamEye [URI] というソフトウェアがある。以下はそのスクリーンショット。
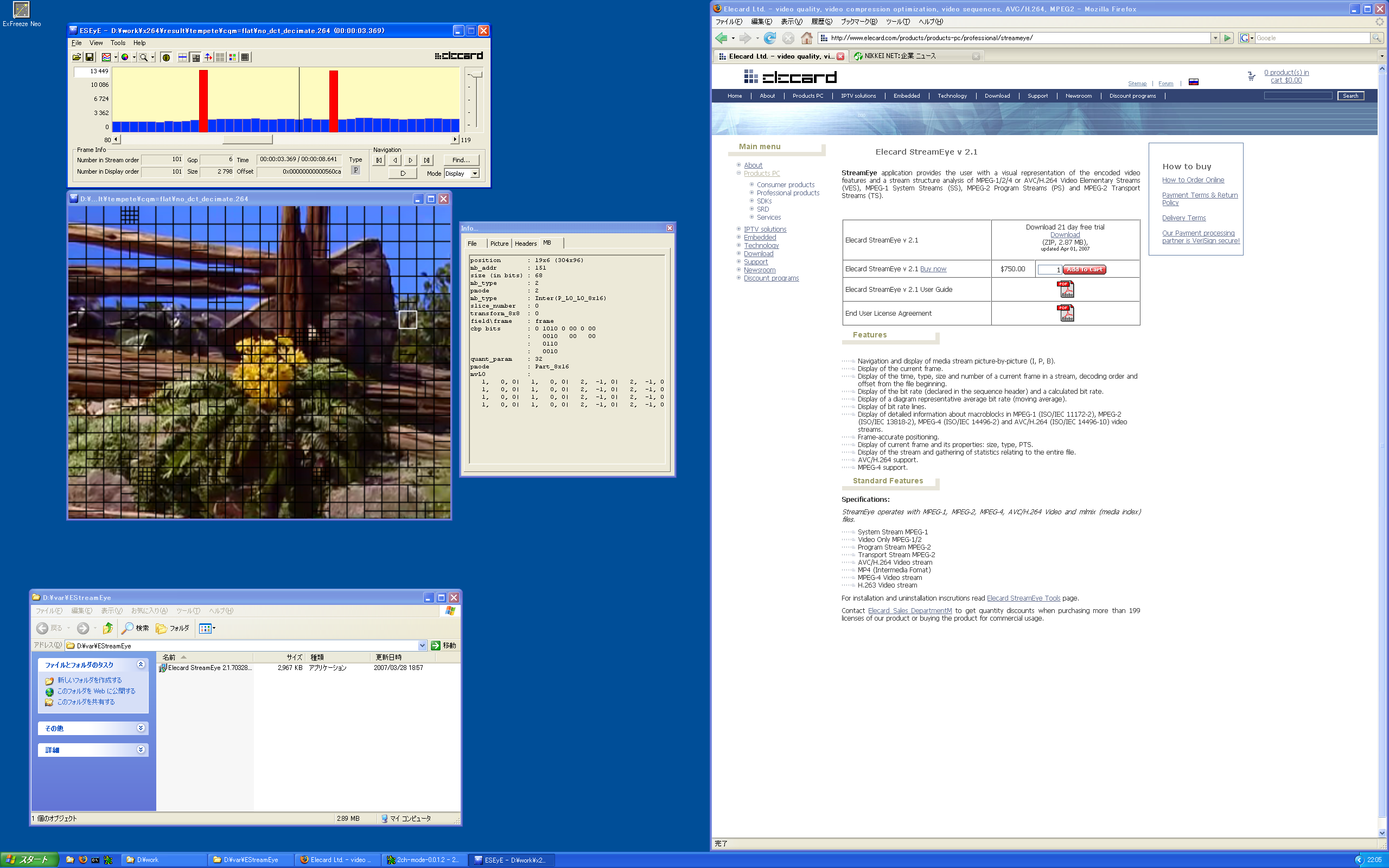
何ができるソフトウェアかというと、H.264 のストリームを読んで MB 分割タイプや、MB の消費ビットや MV とかを確認することができるものだったりする。
この手のソフトウェアには、ニコンシステムのもの [URI] や interra の vega シリーズ [URI]、Mindigo Analyzer [URI] と色々あるのだけど、Elecard の StreamEye は価格がたったの $750 と個人でも手の届く製品になっている。
まー実際のところエンコーダの中の人ぐらいしかこの手のソフトって必要としないから、どーしても高価になってしまうんだよね。とりあえず、StreamEye は使用期限が 21 日間の試用版がダウンロード可能になっているので、興味がある人は試してみるといいかも。
ここ数日マニア向けの記述が過ぎた気がするので、今回はライトユーザ向けに x264 の出力ログの項目の解説を。x264 のエンコード完了時には次のようなログが出力される。
x264 [info]: using cpu capabilities MMX MMXEXT SSE SSE2 3DNow! x264 [info]: slice I:2 Avg QP:18.00 size: 68548 PSNR Mean Y:42.50 U:44.05 V:45.18 Avg:43.07 Global:42.86 x264 [info]: slice P:182 Avg QP:20.00 size: 39716 PSNR Mean Y:40.74 U:42.89 V:43.99 Avg:41.46 Global:41.35 x264 [info]: slice B:76 Avg QP:21.00 size: 27120 PSNR Mean Y:39.45 U:41.58 V:42.31 Avg:40.13 Global:40.09 x264 [info]: mb I I16..4: 4.6% 72.5% 23.0% x264 [info]: mb P I16..4: 0.5% 15.4% 7.1% P16..4: 37.5% 19.9% 14.0% 2.5% 1.9% skip: 1.2% x264 [info]: mb B I16..4: 0.0% 0.8% 1.7% B16..8: 28.7% 13.2% 25.8% direct: 9.5% skip:20.2% x264 [info]: 8x8 transform intra:65.9% inter:51.5% x264 [info]: ref P 46.3% 42.4% 4.5% 2.9% 1.9% 2.1% x264 [info]: ref B 45.6% 46.1% 3.1% 2.6% 1.4% 1.1% x264 [info]: SSIM Mean Y:0.9699457 x264 [info]: PSNR Mean Y:40.380 U:42.512 V:43.506 Avg:41.082 Global:40.953 kb/s:7251.21 encoded 260 frames, 2.39 fps, 7251.63 kb/s
先頭行は実行環境で利用可能な CPU 拡張機能を表示してるだけであまり意味はない。(Core 2 Duo 環境は酷使が祟ったか、電源ユニットが逝かれてしまったので、これは Athlon64 環境での実行例)
x264 [info]: slice I:2 Avg QP:18.00 size: 68548 PSNR Mean Y:42.50 U:44.05 V:45.18 Avg:43.07 Global:42.86 x264 [info]: slice P:182 Avg QP:20.00 size: 39716 PSNR Mean Y:40.74 U:42.89 V:43.99 Avg:41.46 Global:41.35 x264 [info]: slice B:76 Avg QP:21.00 size: 27120 PSNR Mean Y:39.45 U:41.58 V:42.31 Avg:40.13 Global:40.09
次に、このブロックでは I/P/B のフレーム別に 平均 QP, 平均消費ビット量や平均 PSNR が出力されている。PSNR Mean 以降に表示されているのは、Y:nn.nn, U:nn.nn, V:nn.nn の部分が輝度/色差のプレーン別に、フレーム毎に求めた PSNR を平均したもの。Avg:nn.nn の部分が、フレーム全体 (輝度/色差を合わせて) 求めた PSNR を平均したもの、Global:nn.nn の部分がシーケンス全体で (フレーム/輝度/色差 全てで) MSE を求めてから算出した PSNR になる。
なお --no-psnr を指定した場合は PSNR Mean 以降の部分は出力されない。今回は --qp 20 --ipratio 1.2 --pbratio 1.1 を指定したので P の QP が 20, I の QP が 18, B の QP は 21 でエンコードされている。
x264 [info]: mb I I16..4: 4.6% 72.5% 23.0% x264 [info]: mb P I16..4: 0.5% 15.4% 7.1% P16..4: 37.5% 19.9% 14.0% 2.5% 1.9% skip: 1.2% x264 [info]: mb B I16..4: 0.0% 0.8% 1.7% B16..8: 28.7% 13.2% 25.8% direct: 9.5% skip:20.2%
このブロックの解説が今回の第一目的。ここは、各スライスでどの MB モードがどの程度の割合で選択されたかを示している。I フレームでは I16x16, I8x8, I4x4 の 3 通りしか選択できず、P フレームでは I16x16〜I4x4 に加えて、P16x16, P16x8, P8x16, P8x8, P8x4, P4x8, P4x4 と、スキップ MB が選択可能になる。B フレームでは I16x16〜I4x4 と B16x16, B16x8, B8x16, B8x8, B8x4, B4x8, B4x4 とダイレクト MB およびスキップ MB が選択可能だ。
mb I の行に含まれる I16..4: 4.6% 72.5% 23.0% の項目はそれぞれ左から順に I16x16 モードを選択した MB の割合、I8x8 モードを選択した割合、I4x4 モードを選択した割合を示している。mb P の行および mb B の行に含まれる I16..4: の項目もそれぞれ意味は同じだ。
mb P の行に含まれる P16..4: 37.5% 19.9% 14.0% 2.5% 1.9% の項目はそれぞれ左から順に、P16x16 モードを選択した割合、P16x8 又は P8x16 モードを選択した割合、P8x8 モードを選択した割合、P8x4 又は P4x8 を選択した割合、P4x4 を選択した割合を示している。また、skip: 1.2% の部分は P フレームの中でスキップ MB が選択された割合を示している。
mb B の行に含まれる B16..8: 28.7% 13.2% 25.8% の項目は、左から順に B16x16 を選択した割合、B16x8 又は B8x16 を選択した割合、B8x8 を選択した割合をそれぞれ示している。B8x4, B4x8, B4x4 は x264 が対応していないために最初から選択されないので表示欄も用意されていない。direct: 9.5% の部分はダイレクトモードを選択した割合を示していて、skip: 20.2% は B フレームの中でスキップ MB が選択された割合を示している。
x264 [info]: 8x8 transform intra:65.9% inter:51.5%
このブロックはもう見たマンマで、8x8 DCT が採用された MB の割合を示してる。この場合だと、イントラ MB (I16x16〜I4x4 のこと) の 65.9% で 8x8 DCT が選択されていて、インター MB (P16x16〜P4x4, B16x16〜B4x4, ダイレクト MB およびスキップ MB) の 51.5% で 8x8 DCT が選択されてることを示している。
x264 [info]: ref P 46.3% 42.4% 4.5% 2.9% 1.9% 2.1% x264 [info]: ref B 45.6% 46.1% 3.1% 2.6% 1.4% 1.1%
このブロックの解説は今回の第二目的。ここはインター MB が、動き補償の際にどのフレーム (今回は --interlaced をつけてエンコードしたのでフィールドだけど、通常用途ではフレームのはず) を参照したかの割合を示している。
ref P の行は P フレームでの参照状況を示していて、ref B の行は B フレームでの参照状況を示している。各数字は左ほど近く右に行くほど遠いフレームを示していて、ref P の行を例にあげると、一番左の 46.3% という数字は一番近い参照フレームからの予測でエンコードされたブロックの割合が 46.3% だということを示している。
x264 [info]: SSIM Mean Y:0.9699457 x264 [info]: PSNR Mean Y:40.380 U:42.512 V:43.506 Avg:41.082 Global:40.953 kb/s:7251.21
このブロックは SSIM および PSNR (どちらも画質評価の指数) を表示している部分。フレーム種類毎に分けたものではない、シーケンス全体での数値を示している。SSIM に関しては --no-ssim オプションを指定すれば表示されず、PSNR 部分も --no-psnr を指定していれば表示されない。
今回のサンプルログの取得に使ったエンコードソースは VQEG の football (720x480 29.97fps 260frame) で、コマンドラインオプションは以下のとおり。
--keyint 300 --min-keyint 5 --bframes 2 --ref 3 --interlaced --qp 20 --ipratio 1.2 --pbratio 1.1 --partitions all --direct spatial --weightb --me umh --subme 7 --no-chroma-me --bime --mixed-refs --b-rdo --8x8dct --no-fast-pskip --no-dct-decimate --cqm jvt
x264 の --partitions はどの MB モードを有効にするかを指定するためのオプション。多くのモードを有効にすればそれだけエンコード時間が増加するけど、その分画質 (RD 性能) はよくなる……ということになっている。
利用可能なモードがもっとも少なくなるのは --partitions none を指定した場合で、この場合は I16x16, P16x16/skip, B16x16/direct/skip だけが有効になる。そして、利用可能なモードが最も多くなるのは --partitions all のときで、この場合は B8x4〜B4x4 以外の全ての MB モードが有効になる。
さて、最初に「有効な MB モードが多ければそれだけエンコード時間が増加するけど、その分画質が良くなる」と書いたけど、中には例外もある。その例外が --partitions "p4x4" で有効になる P8x4/P4x8/P4x4 モード。
x264 [info]: using cpu capabilities MMX MMXEXT SSE SSE2 3DNow! x264 [info]: slice I:2 Avg QP:18.00 size: 68548 PSNR Mean Y:42.50 U:44.05 V:45.18 Avg:43.07 Global:42.86 x264 [info]: slice P:182 Avg QP:20.00 size: 39716 PSNR Mean Y:40.74 U:42.89 V:43.99 Avg:41.46 Global:41.35 x264 [info]: slice B:76 Avg QP:21.00 size: 27120 PSNR Mean Y:39.45 U:41.58 V:42.31 Avg:40.13 Global:40.09 x264 [info]: mb I I16..4: 4.6% 72.5% 23.0% x264 [info]: mb P I16..4: 0.5% 15.4% 7.1% P16..4: 37.5% 19.9% 14.0% 2.5% 1.9% skip: 1.2% x264 [info]: mb B I16..4: 0.0% 0.8% 1.7% B16..8: 28.7% 13.2% 25.8% direct: 9.5% skip:20.2% x264 [info]: 8x8 transform intra:65.9% inter:51.5% x264 [info]: ref P 46.3% 42.4% 4.5% 2.9% 1.9% 2.1% x264 [info]: ref B 45.6% 46.1% 3.1% 2.6% 1.4% 1.1% x264 [info]: SSIM Mean Y:0.9699457 x264 [info]: PSNR Mean Y:40.380 U:42.512 V:43.506 Avg:41.082 Global:40.953 kb/s:7251.21 encoded 260 frames, 2.39 fps, 7251.63 kb/s
上は昨日説明に使ったサマリーログで、下は --partition all から --partition "p8x8,b8x8,i8x8,i4x4" (デフォルトと同じ) に変更した場合のサマリーログ。
x264 [info]: using cpu capabilities MMX MMXEXT SSE SSE2 3DNow! x264 [info]: slice I:2 Avg QP:18.00 size: 68548 PSNR Mean Y:42.50 U:44.05 V:45.18 Avg:43.07 Global:42.86 x264 [info]: slice P:182 Avg QP:20.00 size: 39608 PSNR Mean Y:40.77 U:42.90 V:44.00 Avg:41.48 Global:41.38 x264 [info]: slice B:76 Avg QP:21.00 size: 27089 PSNR Mean Y:39.46 U:41.57 V:42.31 Avg:40.13 Global:40.09 x264 [info]: mb I I16..4: 4.6% 72.5% 23.0% x264 [info]: mb P I16..4: 0.5% 16.9% 6.7% P16..4: 37.1% 21.3% 16.4% 0.0% 0.0% skip: 1.2% x264 [info]: mb B I16..4: 0.0% 0.8% 1.7% B16..8: 28.7% 13.4% 25.8% direct: 9.3% skip:20.2% x264 [info]: 8x8 transform intra:68.6% inter:55.1% x264 [info]: ref P 46.7% 42.2% 4.4% 2.8% 1.8% 2.0% x264 [info]: ref B 45.5% 46.1% 3.1% 2.7% 1.6% 1.1% x264 [info]: SSIM Mean Y:0.9699681 x264 [info]: PSNR Mean Y:40.397 U:42.521 V:43.519 Avg:41.097 Global:40.968 kb/s:7234.17 encoded 260 frames, 2.50 fps, 7234.59 kb/s
注目すべきポイントは次の 3 行。
all> x264 [info]: mb P I16..4: 0.5% 15.4% 7.1% P16..4: 37.5% 19.9% 14.0% 2.5% 1.9% skip: 1.2% def> x264 [info]: mb P I16..4: 0.5% 16.9% 6.7% P16..4: 37.1% 21.3% 16.4% 0.0% 0.0% skip: 1.2% all> x264 [info]: PSNR Mean Y:40.380 U:42.512 V:43.506 Avg:41.082 Global:40.953 kb/s:7251.21 def> x264 [info]: PSNR Mean Y:40.397 U:42.521 V:43.519 Avg:41.097 Global:40.968 kb/s:7234.17 all> encoded 260 frames, 2.39 fps, 7251.63 kb/s def> encoded 260 frames, 2.50 fps, 7234.59 kb/s
まず、all の側は P16..4: の部分で 2.5% 1.9% と P8x4/P4x8 モードと P4x4 モードが僅かに存在しているのに対して、def の側は P8x4/P4x8 モード、P4x4 モード共に 0.0% 0.0% と存在しなくなっている。--partitions オプションで無効にしているのだから当然なのだけど。
で、PSNR Mean の行では all の側が Y:40.380 に対して def の側が Y:40.397 と P8x4/P4x8/P4x4 が有効になっている all の側で画質が悪化し、kb/s: も all 側が 7251.21 に def 側が 7234.17 と、all の側が発生データ量も増えている。
さらにエンコードスピードも all 側が 2.39fps に対して def 側が 2.50fps と all の方が遅くなっている。まー計算しなきゃいけないモードが増えるから遅くなるのは当然なんだけど。
まとめると、このソースと設定に対して --partitions all を指定して P8x4/P4x8/P4x4 モードを有効にすると、エンコードスピードは遅くなり、画質は悪化し、消費データ量も増えるという、まったくもって良いところがない素晴らしい結果となる。さらに、この傾向は大抵のソースでも同様だったりするので、開発者自身が p4x4 を非推奨にしていたりする。
なぜこんな傾向がでるかを軽く説明する。8x4/4x8/4x4 サブマクロブロックモードを使う場合、各サブブロックに、参照フレームインデックスと差分 MV を出力しなければいけなくなる。一般に、そんなもののために余計なビットを消費するぐらいなら、素直に予測差分を DCT 係数の形で出力した方がマシな結果になることが大半だったりする。そーゆー無駄なモードも評価しろというオプションが p4x4 (および all) な訳で、こーゆー結果になるのも当然だったりするのだな。あと、8x8 よりも小さなサブブロックでは 8x8 DCT が使えない (4x4 DCT 固定になってしまう) のも画質を悪くしている原因の一つだ。