設問「次のコードを読み、選択肢の中から正しいものを選択せよ」
| A |
if(status == ERROR){
exit(EXIT_FAILURE);
}
do_something();
|
| B |
if(status != ERROR){
do_something();
}else{
exit(EXIT_FAILURE);
}
|
| 選 択 肢 |
|
別に何の引っかけもない素直な問題なので、解答から。Pentium 以前の CPU であれば、3「どちらも速さは変わらない」が正答。Pentium II 以降の投機実行をサポートした CPU であれば2「B の方が A よりも速い」が正答になる。
まずコードの解説。何か目的の処理を行う前にエラーチェックを行って、エラーだったら、処理を中断。問題なければそのまま実行というごく単純なコード。実行速度というのは当然だけれどもエラーだった場合の実行速度ではなく、エラーがなく、正常に実行される場合の速度のことを意味してる。
で、何故 Pentium II 以降の CPU だと実行速度に差が出るのかは……タイトルにも書いてる投機実行のせい。
Pentium II 以降の Intel 製 CPU には投機実行というものが追加されていて、時間のかかる&パイプラインが中断されてしまう条件分岐(if 文とか)の際に、多分こっちにいくだろうという予想をして、比較結果がでる前から予測先の処理を行っておくという機能が追加されている。
予想が当ればなにも問題は発生しない。処理の重い比較の間にも計算が進められて高速化できる。しかし、問題は予測が外れた場合。この場合、いままで間違った予測を元に進めていた計算結果をすべて破棄して元の状態にもどし、再度正しい分岐先の計算をしなければいけなくなる。
設問のコードの場合、投機実行はエラーの方に進むと予測してもらうのでなく、正常な処理の方で進めてもらいたいと大抵の場合は考えるだろう。だが、if 文の場合、条件が真になる方向が投機実行の予測先なので A のコードを実行した場合、投機実行に失敗(exit に進むものと投機実行される、実際には do_something に進むことが殆んど)して 10 〜 20 cpu サイクルのペナルティを払うことになるのだ。
B のコードでは、投機実行の予測先が正しいので高速に処理される。投機実行の恩恵をフルに受けることができる訳だ。速度差は、条件分岐の部分だけを比べると A の方が B よりも 10 倍以上遅いという結果になってしまう。
なんでこんなことを書いてるかと言うと、m2v.vfp でもろにこれの効果を体験したせい。コードは多少違って、次の形だけど。
| A |
if(w > 2048){
w = 2048;
}else if(w < -2048){
w = 2048;
}
return w;
|
| B |
if(w > -2048){
if(w < 2048){
return w;
}else{
return 2048;
}
}else{
return -2048;
}
|
一応コードの解説をしておくと、w が -2048 〜 2048 の範囲にあればそのまま w を使って、外れてれば限界値を使うというのが目的。何処で使うかというと DCT 係数を逆量子化した後、IDCT 関数にかける前に使う。まあ、実際にやる必要があるかは疑問なのだけど、一応規格書にはやっとくようにと書いてあるので、A のコードで実行していたわけだ。
それを B 形式に書き換えてみたところ、デコードに必要な時間がトータルで約 5% 短くなったという次第。チェックを省いた場合と変わらないパフォーマンスが得られる。
ただ、ここみたいに分岐確率が 99:1 みたいな場所ならば投機実行はパフォーマンス向上に寄与するだろうけれども、分岐確率が 1:1 な場所ではトータルのパフォーマンスはどうなるんだろうというのが疑問点。
分岐確率 1:1 でもトータルでは投機実行しない場合と変わらないというなら良いのだけど、トータルでパフォーマンスが悪くなるとすると何の為にあるのかな〜とか考えてしまう。まあ確率が 1:1 ってのは少いから良いのかもしれないけど。
Intel から Vtune Analyzer 4.5 のデモ(30日間限定)版を入手したので m2v.vfp の関数毎 CPU 占有率を調べてみた。
結果は実に予想外というか、まあ考えてみれば当たり前なのだろうけれども……、YUV420 -> YUV422 への補間が 8%、YUV422 -> YUV444 の補間が 14%、YUV444 -> RGB への変換が 18% で、YUV420 を RGB に変換するトータルだと 31% も CPU を使ってる。
ここがダントツのトップで、IDCT は 12% 程度、MC は 10% 程度、next_start_code が 15% も使ってるのは多分起動直後から1分間の測定だからで、長時間のデコードの場合はもう少し下がるはず。
わはは、YUV -> RGB がこんなに重いとは予想外だった。つーことは、ここを最適化してやればかなり速くなると期待できる訳で、やる気も出てくるというもの。
バグ情報。0.1.7 には、フィールドピクチャとフレームピクチャが混在してるビットストリームでデコードがおかしくなるバグあり。あと、P ピクチャ内のイントラマクロブロックで PMV をリセットしてしまうというバグも発見。既に解決済みなので、最適化の方が順調に進めば明日にでも 0.1.8 をリリースします。
YUV -> RGB 変換がちぃぃっとも速くなってくれない。まず YUV -> RGB 変換で各項を求めるのに計算していたところをテーブルに置き換えてみたが、これは失敗。実に 5% も遅くなってくれた。さらに I/O のアドレスを配列の添字で計算していたところをポインタのインクリメントに置き換えてみたがこれも失敗。2% 遅くなる。
やはり VC の最適化に任せておいた方が効率が良いらしいというのが教訓。どうやら抜本的に速くする為には SIMD 化を考えなければいけないらしい。
SIMD 使えば YUV -> RGB 変換が4つ並列で動くから、計算速度は 1/3 ぐらい(メモリ I/O が変わらないので 1/4 は無理)になってくれるはず。その場合、えーと 22% の 1/3 だから、約 14% 削れる。6 fps は余裕で越せるな。がんばろ。
YUV -> RGB の MMX 化に関する資料というと、まず最初に出てくるのが Intel のデベロッパサイトで MMX YUV と入れて検索すれば出てくる YUV12(420) -> RGB のサンプル。
ただ、これは出力フォーマットとしては RGB24, RGB16, RGB8 に対応しているくせに、入力フォーマットが YUV420 のみであるため参考程度にしか使えない(プログレッシブ YUV420 にならそのまま使える)
MPEG-2 だと YUV420 でもプログレッシブ形式とインタレース形式があり、さらに YUV422 や YUV444 も有り得る為、一応それぞれ対応してやらなければいけなかったりする。
で、別の資料としては huffyuv の YUV -> RGB のコードというのもあるのだけど、こちらは UYVY 形式(メモリ内に U, Y0, V, Y1 の順序で存在する YUV422 形式)で固められてるため、MPEG VIDEO のデコードで使われる Y, U, V それぞれが別々のメモリの塊として存在する形式にはやっぱり利用できない。一応 B1B0, G1G0, R1R0 を 00_R1G1B1R0G0B0_00 に並び替えてるところとかは参考になるんだけど。
で、結局上記2つの資料とかを参考に自力で書くしかない訳だったりするのだ。悲しいことだけど。
今どれくらい進んでいるかと言うと、MMX 命令のリファレンスマニュアル読みながら、どの命令が使えるか、8 個の MMX レジスタをどう利用するかとかを考えているところだったりする。
Intel のサンプルでは YUV420 をテーブルを使って R3G3B3R2G2B2R1G1B1R0G0B0 に直接変換しているみたいだけど、huffyuv では YUV422 を R1R0G1G0B1B0 に変換してから R1G1B1R0G0B0 に並べ替えている。判りやすさでいうと huffyuv のコードなのだけど、どちらを採用するべきか……。問題が山積み。
m2v.vfp ひどいバグ入れてました。輝度のイントラブロックの逆量子化行列で間違って非イントラブロック用の行列指定してます。Ver. 0.1.8 でのエンバグです。今日中に直して Ver. 0.1.10 に置き換えます。(そうか、YUV -> RGB 変換は無関係だったか)
MPEG のデフォルトの逆量子化行列(イントラブロックでは低周波ほど高精度で高周波では低精度、非イントラブロックでは全部同じ精度)使ってるような MPEG-2 ではひどいブロックノイズが出てるはずです。
Ver. 0.1.8/9 を落とした人は、使わないようにしてください。
YUV444 -> RGB の MMX 化成功。一応速度も向上して正しく動いているようなので、m2v.vfp Ver. 0.2.0 として公開しました。場所は例のごとく こちら です。
0.2.0 でなにか問題が発生した場合は障害報告をしてから、こっち に 0.1.x 系最終版の 0.1.10 があるので、使ってみてください。(容量が最近ぎりぎりなので、この方法で公開を継続できるか判りませんが)
んー、真面目な話はここまでで、後は不真面目な話。
YUV444 -> RGB 処理の MMX 化だけど、期待していたよりも早くなってはくれなかった。何も考えずに素直に C で書いて、VC に最適化を任せた場合と比較して、MMX 化をすれば 1/3 ぐらいになるだろうと期待していたのだけど、せいぜい 1/2 程度にしかなってくれなかった。(それだけ早くなれば十分じゃないかという意見もある)
今までのコードだと、比較用に使ってる 450 フレームの m2v を 82 sec で処理できてて、このうち YUV444 -> RGB 処理に 20% 食われている。で、今回 YUV -> RGB 処理を MMX 化することで同じ m2v を 74 sec で処理できるようになったから、約 10 % の高速化。つまり、YUV -> RGB を 20% から 10% に、半分に削ることができた計算になる。
メモリ入出力の速度は変わらないけど変換計算自体は4つ並列に動かせるから 1/3 ぐらいになるかと期待していたのだけど、結果は 1/2 どまり。まあ、コーディングの効率が悪いせいなんだろうけど……。
手動でアセンブラコードの最適化するのはな〜。不毛だからやりたくないというのが本音。まあ2倍に早くなってくれたことで満足して、別の関数(YUV420/422 -> 444 の補完)を MMX 化することにしよう。
スターチャイルドの DVD ソフト「Di・Gi・Charat」 Vol.1 を購入した。
既に発売当初からあちこちの掲示板で「画質最悪」「金返せ」「何故2枚にわけた」「見てると仕合せになれる」と評判だったので買うつもりは無かったのだけど、とある事情により必要になったため仕方がなく購入。
まあ、用事は済ませたので、普通に PowerDVD 2000 で鑑賞していたのだけど、評判どおり画質悪いね〜。
モスキートノイズはブンブン飛びまくってるし、所々にブロックノイズまで見える。特に、OP が最悪。ブラックアウトとフラッシュが多い MPEG 向きじゃないソースなのは確かにその通りなのだけど、それにしてもひどすぎる。
思わず DeCSS とかで抜いてからデバッグモードで動かしてる m2v.vfp に入れてど〜なってるのか中を覗いて見ようかとも考えたのだけど、悲しいことに現在の日本の著作権法ではそれをやってしまうと後ろに手が回ってしまうので実行できない。
確か、現在の著作権法だと DeCSS のような「複製防止機能を解除」するような装置は「作っちゃ駄目、売っちゃ駄目、持ってても駄目(あれ、研究目的なら持っててもいいんだっけ?)」という事になっているので「DeCSS 持ってま〜す。使ってみました〜」とか書いてしまうと翌日には警察がやってきて、コンピュータ一式を証拠品として押収した挙げ句、刑事裁判でボコボコにされてしまったりすることもありうるわけ。
え、DeCSS 全部を取締まることなどできないから起訴される心配は無い? 何寝惚けたこと言ってるんですか、たとえ全員を逮捕することなどできないにしても、一人上げてしまえば見せしめとしての効果が出て、違法行為の再発防止という効果が見込めるじゃないですか、国家権力を甘く見ちゃいけません。
そういうわけで「Di・Gi・Charat」の中がどうなっているのかは、判らない。何しろ、複製防止機能で保護されてるから、これを解除する事はできない。
なので、9,200,000 bps の CBR でエンコードされてるとか、一般的な IBBPBBPBBP の GOP 構造ではなく、IBPBPBPBPBP という GOP 構造なので I ピクチャ間に P ピクチャが多くなり、P ピクチャ毎に画像が劣化してモスキートノイズが増えてるとか、動き検索が根性無しで、B/P ピクチャでもすぐに I ブロックを入れるとか、一応フィールド MC・フィールド DCT には対応しているらしい等と言ったことは判らない。
決して判ることはないのだ。もしもこれが事実だったとしてもそれは偶然の一致。
m2v.vfp の方は、とりあえず最適化があるていど区切りがついたら、システムストリームの対応を考慮する予定。……なのだけど
困ったことに ISO/IEC 13818-1 が未だに入手できてないのはどうしたら良いものやら。
正確に言うと、Wotsit's Format で一応ファイルは入手できたのだけど、旧バージョンの Word DOC な為、私のところで開くと「化け化けは定義されていません」とやらで埋め尽くされたものしか表示されないのだ、悲しいことに。
む〜「最新 MPEG 教科書」にも少しは情報が記述してあるのだけど、プログラムを書くのに参考になるかと言うと……ちょっと心もとない。
bbtool とかのソースを参考に書くという手もあるのだけど……、やっぱりそれしかないのかな〜。MPEG2DEC よりも遥かにソースはきれいだから読みやすいし。
本当は規格書そのものを、ドラフトでも良いから入手できればそれが一番なんだけど。特に MPEG-2 の場合は、規格書がそのまんまデコーダの作り方だったりするから、実に参考になるのだけど。個人じゃ入手は難しいから諦めるしかないのかも。
ああ、何処かに落ちてないかな〜。
ブロックデータ -> フレーム再構成の MMX 化が終了したので、m2v.vfp に組み込んで性能の変化を測定してみた。すると、驚くべきことに、今まで 70 秒かかっていた作業が 46 秒で済むようになっている。
何が起こったのだろうと疑問に思いつつ「そうか、ここ(今回 MMX 化した部分)はそんなに重い処理だったのか」と納得して、10分程は仕合せな気分に浸れたのだが……。
それじゃ再測定してみるかと思ってもう一度動かそうとすると、何故かファイルが少い。本当なら 450 枚の連番 BMP ファイルが作成されているはずが、1つしかファイルが存在しない。
……つまり……、本当なら連番 BMP で出力するところを、単一ファイルに出力していたため、HDD への書き込みが発生せず、それで 70 秒から 46 秒に縮まったということ?
あの喜びは……何だったのだろうとちょっと憂鬱になってしまった。(今度はきちんと連番 BMP で出力して)再計測してみると、速度は MMX 化前とほとんど変化していない。
む〜。まあ、こういうこともあるよね。今日は m2v.vfp の更新は無し。次は MC の MMX 化が進展を見せた時の予定。
というわけで、しばらく前の予告のとうり、トップページのデザイン変更して旧コンテンツへのリンクは削除しました。
居ないと思いますけど、旧コンテンツの更新を心待にしていたという方、申し訳ありませんが、今後更新の予定はありませんので、そーゆーことで諦めてください。一応ファイルは残っていますが、今後情報が追加されることは、まずありません。また、来年3月にはファイルも消えてしまうでしょう。
コンテンツ紹介の文を考えるのが面倒だったので、シンプルなタイトルリンクとなってます。そのうち、何とかするかもしれません。ま、適当に見てってください。
悪友Kが浮動小数点 IDCT を SSE 化してくれたので、m2v.vfp に組み込んでみたのだが……。えーと、使いたい場合は IDCT に浮動小数点を選んで、SSE にチェックをつければ使えるようになるはず。
ただし、ほんのちょっとしか速くならないので、そこのところは覚悟しとくように。糞遅かった浮動小数点 IDCT がほんのちょっと速くなるだけっすから。
とりあえず組み込んで公開すれば、すこしはプレッシャー感じてもう少し速くなるように努力してくれるかな〜と期待しての行動だったり。
さて、m2v.vfp も Ver. 0.2.3 でいよいよ MC の MMX 化も終ってしまったので、IDCT の MMX 化を考えなければいけないのだけど……。
む〜。アルゴリズム判ってないのが致命的だよな〜。他の人が公開してる IDCT のソ〜ス使うっていう手もあるんだけど。ま、それは最後の手段ということで。どこまでできるかやってみることにしましょう。
悪友Kから新版の SSE IDCT が送られてきたので早速試してみる。うーん、旧版とは大違いの速度向上。あれはなんだったんだと言いたくなってしまうな。
一応、為念、まだ整数 IDCT の方が早いので、そこのところは勘違いしないでね、精度は……多分 SSE 版の方が上のはずなんだけど、IEEE-1180 のテストプログラムに通してみたわけじゃないので、不確実。
む〜、こりゃこっちも怠けてる訳にはいかないな〜。ホントは AIR とかやってみたいのだけど、丁度貧乏なことだし、しばらくは整数 IDCT の MMX 化頑張ってみよ。
ちいっとばかし m2v.vfp 関連のロードマップというか、TODO リストといったものを、メモも兼ねて。優先順にこんな感じ
まず、現在進行中の最適化(SIMD 化)作業。とりあえずこれは残すところ整数 IDCT の MMX 化のみ(後、各 ASM コードの最適化とかもあるのだけど、これはど〜しよ〜かな、やらなくても良いかも)
で、最適化にけりがついたら、システムストリームへの対応。とりあえずはプログラムストリームのみの予定で、トランスポートストリームには当面手を出すつもりはなし。
プログラムストリームも読めるようになったら、MPEG-1 AUDIO もデコードできるようにして、VFAPI から利用できるようにしたい。これは……、mpg123 のソースを参考にすれば(mpg123 のソースってソースレベルでの最適化目一杯かけてあるからすごく読みにくいのだけど)何とかなるはず。
ここまでできたら、次は I ピクチャ単位で MPEG2 のカット編集可能な GUI の作成。とりあえず、ここまでが第一期目標。できれば今年中に片付けたいところなのだけど、無理かも。来年になってしまうかもしれない。
後はおまけというかできたらいいなレベルの話で、MPEG Audio の代りに LPCM や DTS や AC3 が入ってるのでも、そのままカット編集できるようにして、最後に部分再圧縮によるフレーム単位カット編集ができるようになれば完璧の予定。(今年中には絶対無理だな〜)
問題点としては、そろそろ夏休みも終ってしまうので、フルタイムにコードを書けなくなってしまうことなんだよね〜。卒研の方ももうすこし真面目にやらなきゃいけないし……。
あ〜、やっぱり物理学科選んだのは間違いだったかな〜。情報にしとけば m2v.vfp そのまま卒研にできたらしいし(もっとも情報に進んでいたらスポイルされて m2v 作れなくなってたかもしれないけど)
んと、ホントは m2v.vfp への余所で公開されてる IDCT 関数の組み込み方とか書くつもりだったのだけど、その前に、関数ポインタについてある程度解説しといた方が良いかと考えたので。
まず基本的に、通常用途では関数ポインタを使用する必要は無い。ので、まあ覚えなくても良いのだけど、例えば DLL を明示的にロードして利用する場合とか、C でオブジェクト指向っぽいプログラミングをする場合に必要になったりするので、余裕があれば覚えておいた方が役に立つ。
まず、コンパイル後の C プログラムでは、関数は CPU に対する命令が書き込まれたメモリの塊として存在する。そして、関数の呼び出しは、その 関数=メモリの塊 の先頭に対するコール(戻ってくるジャンプ)として実行される。
さて、ここで C の初歩であるポインタについて思い出して欲しい。ポインタとはメモリのアドレスを記憶している変数であった。そして、関数とはメモリの塊だ。では、ポインタに関数の先頭アドレスを代入しておき、関数呼び出しではそのポインタが示すアドレスにコールするようにしたらどうなるだろう。
……これが C による関数ポインタの基本思想。簡単でしょ。(続きは明日)
さて、いよいよ本題に……入る前に。IDCT の組み込み以前に、普通の人は ASM ソースのアセンブルなんてできないから m2v.vfp はビルドできないぞという突っ込みが某方面より入ったので。
MASM の入手方法とか VC 環境での使い方とかは下の URI を参照してください。
http://www.geocities.co.jp/SiliconValley-PaloAlto/5989/masmp01.html
本題。m2v.vfp の中で IDCT を呼んでいるのは picture.c の decode_picture() という関数。ループの奥の奥の方に prm->idct_func(block) とかいうのがあると思うけど、それが IDCT 関数の呼び出し部分。
この prm->idct_func というのが昨日説明した関数ポインタ。このポインタには M2V を開くときに各 IDCT 関数の実体へのポインタを入れてある。
具体的に何処かというと、mpeg2video.c の select_idct_func() この関数自体は open_mpeg2video() から呼ばれる。
こういう風に関数ポインタを使うことの利点は、呼び出し側の手間を軽減できること。一々 IDCT 呼ぶ毎に MMX がど〜の浮動小数点がど〜のとチェックしてたのでは遅くなっちゃうし、コードも煩雑になるでしょ。
さて、あちこちで公開されてる IDCT 関数のソースを m2v.vfp に組み込む場合だけど、要は select_idct_func() をちょいちょいと書き換えて関数ポインタに代入してるところを手直ししてあげればそれだけで終了。後は追加した IDCT 関数のソースを Makefile に足して nmake で完成。VC の統合環境使ってる場合はまあ、適当に空 DLL のプロジェクト作成してファイル追加して公開する関数をリンカオプションで指定してあげれば完成。
IDCT 関数の公開元としては MPEG2AVI 作ってる liaor さんの とこ とか、Peter Gubanov さんの ところ とか、後は Intel でも 16bit AAN 版のを公開してたかな。多分探せば他にもあるはず。
なんでこんな簡単なことなのに自分でやらないかというと、世間で公開されてる IDCT ソースには色々と問題があったりするからだったり。で、その問題とは……(明日に続く)
さて、他で公開されている IDCT 関数の問題点。
例えば、liaor さんが公開してる IDCT 関数群は、行と列を転置した DCT 係数しか受付けてくれない。ので、m2v.vfp で使う場合には今使っている IDCT 関数を行列転置したデータを受付けるように変更するか、入手した IDCT 関数を転置していない行列を受付けるように改編しなければいけない。
今まで使ってた関数と互換性が無くなるのを覚悟して入れてみたところ、idct_mmx32 の場合かなり高速化(比較用に使用している TMPGEnc で作成した 15 秒の動画ファイルで int32 と比較して 5 秒短縮)できるのだけど、他の IDCT 関数と互換性が無いので現在の m2v.vfp には使えない。
次に、Peter Gubanov さんの公開している IDCT 関数の場合。こちらは行列転置していない普通の DCT 係数を受付けてくれるのだけど、その代り liaor さんが作ってるのほど早くない。同じ動画ファイルで 2 秒しか短縮しない。(ので、どうせなら自分で書くかとか考えてしまう)
Ver. 0.2.6 で m2v.vfp の整数 IDCT 関数を IJG (Independent JPEG Group) の LLM 版ソースをベースにしたものに変更したのだけど、何故こんな事をしたかというと……。
うん、いずれ MMX 化するためにアルゴリズムを理解しようという意図もある。
ただねここだけの話、ホントは……設定ツールで整数 IDCT のアルゴリズムを 32bit LLM とか書いてたくせに、実はコメント良く読んでみると、MSSG の整数 IDCT が Chen-Wang のアルゴリズムを使ってるということに気が付いてしまったのだな〜。
Chen-Wang のアルゴリズムの方が 高速 IDCT のアルゴリズムとしては元祖らしく、要素 8 の1次元 IDCT につき掛け算11個と足し算29個で済む(これは LLM も同じ)ものなのだけど、LLM のアルゴリズムの方が同じ計算が多いので MMX 化しやすい……らしい。良く判ってないけど
というわけで、設定ツールの説明に実体をあわせたというのがホントのところ。実はこの変更で少〜し遅くなってしまってる(DCT 係数の読み取りを最適化したのでトータルでは早くなってる)
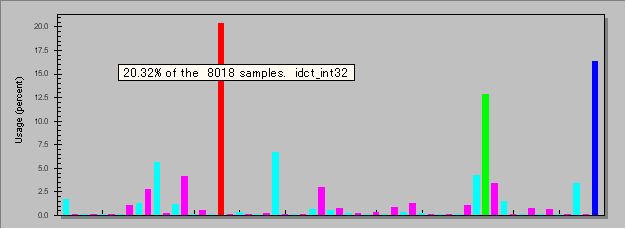
例えば、m2v.vfp Ver. 0.2.7 を、Vtune Analyzer (Intel で 30 日間体験版がダウンロード可能)で測定してみると、次のような各関数毎の CPU 使用率のグラフが表示される。
一目瞭然、IDCT が全処理の 1/4 もの時間を消費していることが判り、なんとしてでも MMX 化せねばという使命感がこう、胸一杯に込み上げてきたりもするワケなのだけど。
実はもう少し、面白い事も判る。右端の青の項目は YUV -> RGB 変換で、約 16 % 使っているのは仕方のないことなのだけど、緑の項目は m2v.vfp 内部のバッファからアプリケーションに単純にメモリの中身をコピーしているだけなのに、なんと 12% も使っている。実はこれが三番目に重い関数だったりするのだ。
PC のボトルネックはメモリ IO だというのは真実だったのだな〜と実感してしまう瞬間。
……さて、YUV -> RGB と単純メモリ間コピーの消費時間(どちらもアクセスするメモリ量は同一)を比較してみると……、なんと YUV -> RGB が計算に使っているのは僅か 4% で残りの 12% はメモリ IO で消費されていると判る。
じゃあ、バッファには YUV のままで置いといて、VFAPI アプリケーションに渡すときに RGB に変換しながらコピーしたらどうなるかな〜とか期待してしまい、捕らぬ狸のなんとやら。
いや、計算通りに進めば 12% 丸々削れて、下手な MMX 化より余程最適化の効果がでるはずなのだ。うぷぷ。こう言う事があるから Vtune は良いよね〜。ホントは体験版だけじゃなくて製品版欲しいのだけど、ちょっと入手方法が面倒なのが厄介なところ。さて、試用期限が切れる前に最適化終わらせましょ〜。
さて、昨日書いた YUV -> RGB 変換とメモリ転送のマージだけど、やってみた結果は実に期待どおり、比較用ムービーで 5 秒も短くなってくれる(約 12% の高速化)大成功だった。というわけで、Ver. 0.2.8 としてリリース。
うん、速くなってくれたのは嬉しいのだけどね……。今までこつこつと MMX 化してきたあの作業は何だったのかな〜、とちょっと空しくなってしまったのも事実。
例えば 0.2.8 で MMX オプションを ON にした場合と OFF の場合で、15 秒の動画をデコードするスピードを比較してみると、大体 7 秒くらいしか変わらない。このうち 6 秒分は YUV -> RGB 処理の MMX 化で速くなった部分だから、YUV のままで表示できるような場合には、MMX 化の効果というのは 1 秒分しかないことになる。
……9月中にやってきたことは一体なんだったのだろ〜とか、ふと人生を振り返ってしまう瞬間。結局メモリ支配的な部分では MMX 化の効果って全然あらわれないんだな〜と、切ない教訓が得られただけ……。
うん、MMX 化するぐらいなら、アルゴリズム変更してメモリアクセスを減らした方が良いというのは、実に健全でありがたい結論なんだけど。
整数 IDCT の MMX 化を昨日から考えてるのだけど、やっぱり行処理では madd 8個と add 8個が限界なのかもしれない。
う〜ん、だとしたら AP-922 と同じ程度の性能にしかならないんだよな〜。とすると、速くなったとしても 2 秒が限界。
列処理は普通に LLM のアルゴリズムのまま 2 並列で動かせば良いから……って、Peter さんの IDCT 関数はそれでやってたはずだからこりゃ絶望かも。
まあ、2 秒短くなってくれれば良し、もっと速くなってくれれば運が良かった、遅いようなら既にあるソースを使うという方針で、とりあえず書いてみますか。
整数 IDCT の MMX 化だが、行処理については何とか madd 5 個と add/sub 10 個でできるようになった。
但し、列処理は精度の問題で2並列が限界。Peter さんのソースは4並列でやってるみたいだけど、どうしてこれでうまく行ってるのかがちょっと疑問。
で、とりあえず組んでみた結果、実にバグバグなごみだらけの画像が表示された。この状態でとりあえずどこまでスピードアップしたかと調べてみたら、やっぱり短くなったのは 2 秒だけ。
……デバッグ止めて、Peter さんのソース使おうかな〜。